

Abstract
Numerous experimental data show that the brain is able to extract information from complex, uncertain, and often ambiguous experiences. Furthermore, it can use such learnt information for decision making through probabilistic inference. Several models have been proposed that aim at explaining how probabilistic inference could be performed by networks of neurons in the brain. We propose here a model that can also explain how such neural network could acquire the necessary information for that from examples. We show that spike-timing-dependent plasticity in combination with intrinsic plasticity generates in ensembles of pyramidal cells with lateral inhibition a fundamental building block for that: probabilistic associations between neurons that represent through their firing current values of random variables. Furthermore, by combining such adaptive network motifs in a recursive manner the resulting network is enabled to extract statistical information from complex input streams, and to build an internal model for the distribution p* that generates the examples it receives. This holds even if p* contains higher-order moments. The analysis of this learning process is supported by a rigorous theoretical foundation. Furthermore, we show that the network can use the learnt internal model immediately for prediction, decision making, and other types of probabilistic inference.
Significance Statement
Most memory models focus on pattern completion as computational operation for memory recall. However, obviously our brains can also answer questions that involve diverse experiences in unexpected ways. Consider for example the question whether we went with Mr. X more often to lunch than to dinner, or whether Mr. X would probably like the new restaurant Z. These queries could not be anticipated during the formation of memory traces. Still we can answer such queries (which are special cases of probabilistic inference: estimation of a posterior marginal) without any effort. We propose a model based on experimentally observed rules for synaptic plasticity (STDP), which explains how a network of spiking neurons can acquire this capability.
Introduction
A large number of experimental data from neuroscience and cognitive science suggest that the brain performs probabilistic inference for a large number of probability distributions p* that describe different aspects of the environment of the organism and its interaction with the environment (Griffiths and Tenenbaum, 2006; Bonawitz et al., 2014). In models for probabilistic inference in networks of neurons one has so far (with the exception of Siegelmann and Holzman, 2010; see Discussion) programmed the underlying distribution p* into the architecture and parameters of the network model. However brains have to learn internal models p of salient distributions p* in their environment from examples that are generated by p*. We present in this article the first model that explains how networks of spiking neurons could learn such internal models p through experimentally supported local plasticity rules. Furthermore, we show how a network of spiking neurons can store the learnt information in a way that makes it readily accessible for probabilistic inference.
Two different approaches how networks of neurons in the brain could execute probabilistic inference have been proposed. One approach emulates an arithmetical (deterministic) algorithmic method for performing probabilistic inference through a suitable distributed organization of sums and products of probabilities (referred to as belief propagation or message passing; Steimer et al., 2009). The other approach for emulating probabilistic inference in networks of spiking neurons is based on the assumption that a network of neurons can “embody” a distribution p in such a way that it can generate samples from p. Probabilistic inference for p can then be performed through simple operations on these samples, for example the computation of a posterior marginal just requires to look at the distribution of the random variable of interest in these samples. This approach is known in computer science as Markov chain Monte Carlo (MCMC) sampling, and is widely used to perform probabilistic inference also for complex distributions p for which belief propagation approaches have no guarantee to provide correct answers. Whereas the previous approach prefers a deterministic network, where every stochasticity is detrimental for the performance, this second approach requires an inherently stochastic network of spiking neurons (Buesing et al., 2011). It has been argued that the dynamics of networks of neurons in the brain is in fact highly stochastic, both on the basis of inherently stochastic features of its components (such as stochastic synaptic release), and on the basis of trial-to-trial variability in neural recordings and observed variability in behavioral outputs.
The learning model that is presented in this article ties in to this second approach, and shows that stochastic networks of neurons are able to automatically absorb the relevant statistical information from examples that they receive. As a result, we have now one first complete theory for the emergence of probabilistic inference in networks of spiking neurons through learning. We focus in this article on somewhat idealized models for spiking neurons and plasticity rules, which allow us to give rigorous proofs for the convergence of learning.
We first show how an extension of an ubiquitous network motif of cortical microcircuits, interconnected populations of pyramidal cells with lateral inhibition (Winner-Take-All (WTA) circuits; Douglas and Martin, 2004; Nessler et al., 2013), gives rise to the basic building block for absorbing probabilistic information from examples. The output neurons of an array of WTA-circuits form the hidden layer of a three-layer feedforward learning module, to which we refer as a “stochastic association module.” We show that such a module can learn through spike-timing-dependent plasticity (STDP) and plasticity of the excitability of neurons (intrinsic plasticity) stochastic associations between the random variables that are encoded by the firing of neurons on its first and third layers. The module can learn this probabilistic information from the statistics of activation and coactivation of these neurons when the network processes examples that are provided by its environment. An important second finding is that recursive combinations of this network module can learn even complex probabilistic relationships between large numbers of random variables. This network learning capability is in fact universal in the sense that the underlying theory implies a proof of principle that an approximation to any distribution p* over discrete random variables can be learnt by exposing the network to examples drawn from p*. In fact, one can show that if the network is too small or has too few connections for learning a close approximation of p*, it will still strive toward approximating p* as well as it can, given its limited resources. The understanding of this learning process is supported by the theory of Expectation Maximization (EM).
Results
Previous models for probabilistic inference in networks of spiking neurons have shown that one can program the parameters (eg, conditioned probability tables) of a given distribution p* over discrete random variables into a network of idealized models for spiking neurons, provided that the network has a suitable architecture. We provide in this article a proof of principle that these parameters of p* do not have to be programmed into the network: they can be learnt by a network N
of spiking neurons via simple local plasticity rules from examples  that are generated by p*. This does not hold for every neural network N
, but like in any existing model for probabilistic inference in neural networks, only under suitable assumptions about the architecture of N
. This result provides a proof of principle that networks of neurons in the brain can not only perform probabilistic inference for distributions p* whose parameters are specified in the genetic code, but also for distributions p* that an organism encounters in its environment.
that are generated by p*. This does not hold for every neural network N
, but like in any existing model for probabilistic inference in neural networks, only under suitable assumptions about the architecture of N
. This result provides a proof of principle that networks of neurons in the brain can not only perform probabilistic inference for distributions p* whose parameters are specified in the genetic code, but also for distributions p* that an organism encounters in its environment.
The underlying theory of EM does not guarantee that p* can be learnt perfectly. However it implies that a network N with a suitable architecture is expected to make progress in creating an increasingly more accurate internal model p for p* when it receives more and more examples that are generated by p*. EM does not guarantee that the internal model p converges to p*, but it implies that the network learning process cannot “run around in circles” where p moves forth and back between better and worse approximations of p*. This learning result is general insofar as it shows that internal models p can be learnt by a network N with a suitable architecture for external distributions p* over any number of discrete random variables, with arbitrary, also higher-order, dependencies among these random variables. However, although the architecture of N will obviously have to depend on the number of random variables of p*, we show that it suffices to assume that it consists of recursive interconnections of different copies of a simple generic network motif, to which we refer as a stochastic association module. This network motif is a three-layer feedforward network of excitatory spiking neurons with lateral inhibition on the hidden layer (see Fig. 2). We show that this simple microcircuit motif can be viewed as an atomic learning module, that extracts via STDP and intrinsic plasticity from examples probabilistic associations between input variables x and output variable z that are encoded through population coding on its input and output layer. An example is presented in Figure 3. We will then show in the following subsection that this atomic learning module can be recursively combined to form a network that automatically approximates through STDP and intrinsic plasticity arbitrarily complex distributions p* over many discrete random variables from examples generated by p*. In other words, this network learns an internal probabilistic model p for its stochastic environment p*. Furthermore, this network has the property that it can readily apply this internal model by carrying out probabilistic inference for p through its inherent stochastic dynamics. Examples are presented in Figures 6–9.
The neurons in our models are stochastic integrate-and-fire neurons, which have been shown to match biological data quite well (Jolivet et al., 2006; Mensi et al., 2011; Gerstner et al., 2014). We assume that a neuron has at any time t the instantaneous firing probability density  , where u(t) is its membrane potential and τ is a time constant. When it fires a spike, the neuron enters an absolute refractory period of duration τ after which it resumes its stochastic firing. The membrane potential
, where u(t) is its membrane potential and τ is a time constant. When it fires a spike, the neuron enters an absolute refractory period of duration τ after which it resumes its stochastic firing. The membrane potential  is assumed to be the sum of the PSPs
is assumed to be the sum of the PSPs  elicited by the spikes from its presynaptic neurons, where wi
is the synaptic efficacy of the i-th synapse (and b is the bias of the neuron). The theoretically best tractable shape of a PSP
elicited by the spikes from its presynaptic neurons, where wi
is the synaptic efficacy of the i-th synapse (and b is the bias of the neuron). The theoretically best tractable shape of a PSP  would be a step function of length τ. However, we show in Examples 1 and 2 that the relevant learning properties also hold for α-shaped EPSPs that are commonly considered in theoretical neuroscience. On the side, we would like to point out that for biological neurons the EPSPs vary from shapes with a pronounced initial peak to shapes with smooth hills in dependence of the distance of the synapse to the soma (Williams and Stuart, 2002), and obtain yet other shapes if amplified through NMDA or Ca spikes (Larkum et al., 2009).
would be a step function of length τ. However, we show in Examples 1 and 2 that the relevant learning properties also hold for α-shaped EPSPs that are commonly considered in theoretical neuroscience. On the side, we would like to point out that for biological neurons the EPSPs vary from shapes with a pronounced initial peak to shapes with smooth hills in dependence of the distance of the synapse to the soma (Williams and Stuart, 2002), and obtain yet other shapes if amplified through NMDA or Ca spikes (Larkum et al., 2009).
We use a simple STDP rule, which has the advantage of being theoretically tractable. Let w be the weight of the synapse at the connection from some presynaptic neuron νpre
to a postsynaptic neuron νpost
. At each postsynaptic spike of neuron νpost
at time t this weight undergoes an update:  , where η is the learning rate and
, where η is the learning rate and (1)
(1)
The parameter w– is a baseline parameter in the learning rule, and τ is a parameter that corresponds to the duration of postsynaptic potentials (PSPs). Figure 1A shows the resulting STDP curve. The rule exhibits LTP only for pre-before-post spiking within a time window of duration τ, otherwise it exhibits LTD. The causal part of the STDP window curve has the same shape as the PSP kernel, which is similar to other theoretically derived plasticity rules (Toyoizumi et al., 2005; Pfister et al., 2006). The properties of this plasticity rule were studied by Nessler et al. (2013). It was shown there that it supports learning of an internal probabilistic model of the inputs in a WTA network. It was also shown there that the weight dependence of Δw in Equation 1 fits quite well to experimental data. Figure 1B shows that the shape of the STDP curve according to Equation 1 looks like the commonly considered one when applying an intermediate pairing frequency of 20 Hz (Sjöström et al., 2001 shows experimental data on the dependence of the shape of the STDP curve on the pairing frequency).

STDP curves of the synaptic plasticity rule. A, The STDP curves show the weight change for a presynaptic spike at time tpre and a postsynaptic spike at time tpost , for different time differences tpost – tpre . The red curve represents STDP for the simple rule that is used in the theoretical derivations. In computer simulations, we used also an STDP rule shown with the blue curve, that has a smoother, more biologically realistic shape. B, The change of the synaptic efficacy after a stimulation protocol where both the presynaptic and postsynaptic neuron fire at a frequency of 20 Hz, for different time differences Δt between a postsynaptic and presynaptic spike. The STDP curve shifts more toward LTP, and depression is no longer time independent due to overlapping PSPs (Nessler et al., 2013, their Fig. 4). This STDP curve is quite similar to experimental data (Sjöström et al., 2001).
It is well known that the excitability of neurons changes in dependence of their history of firing activity (Daoudal and Debanne, 2003; Cudmore and Turrigiano, 2004). We model this intrinsic plasticity of neurons through a simple rule according to which the bias b of a neuron changes at each spike of the neuron according to  , with:
, with: (2)where
(2)where  is a learning rate and b– is a baseline parameter. In addition, we assume that the bias exhibits constant decay according to the differential equation:
is a learning rate and b– is a baseline parameter. In addition, we assume that the bias exhibits constant decay according to the differential equation: (3)
(3)
A network module for learning stochastic associations
The atomic learning module in our model is a simple microcircuit motif that learns associations between some array of random variables  and another random variable z from examples
and another random variable z from examples  that are presented to the network. The variables x and z could for example represent different higher-level features of an image. Or the variables x could represent higher level features of some visual stimulus, and the variable z a feature of a simultaneously occurring auditory stimulus. More formally, we assume that the network is exposed to examples
that are presented to the network. The variables x and z could for example represent different higher-level features of an image. Or the variables x could represent higher level features of some visual stimulus, and the variable z a feature of a simultaneously occurring auditory stimulus. More formally, we assume that the network is exposed to examples  consisting of concrete assignments of discrete values to the variables x and z, that are drawn from some unknown distribution p*(x, z). We want to determine under what conditions a network module is able to create autonomously from exposure to these examples an internal model p(x, z) for p*(x, z), that approximates p* when the number of examples grows. Note that in general the same input x will occur in combination with different values z(1), z(2), . . . of z in the training examples, and the goal of learning is to learn for each value z(i) the probability that it occurs for input x. Hence, the learning performance will not be evaluated by counting errors, ie, deviations from a target output value. Rather, it will be evaluated by how well the network reproduces for any input value x the distribution of output values z.
consisting of concrete assignments of discrete values to the variables x and z, that are drawn from some unknown distribution p*(x, z). We want to determine under what conditions a network module is able to create autonomously from exposure to these examples an internal model p(x, z) for p*(x, z), that approximates p* when the number of examples grows. Note that in general the same input x will occur in combination with different values z(1), z(2), . . . of z in the training examples, and the goal of learning is to learn for each value z(i) the probability that it occurs for input x. Hence, the learning performance will not be evaluated by counting errors, ie, deviations from a target output value. Rather, it will be evaluated by how well the network reproduces for any input value x the distribution of output values z.
We show that a three-layer network of spiking neurons with the architecture shown in Figure 2 can accomplish this learning task through STDP on synaptic connections from the first to the second layer and intrinsic plasticity of excitatory “hidden” neurons α on the second layer. The weights of synaptic connections between the second and third layers are assumed to be fixed. These weights are assumed to have a large value, so that the firing of a neuron α on the second layer causes with very high probability the firing of the neuron on layer 3 to which it is connected.

Structure of a stochastic association module that is able to learn probabilistic associations between multinomial variables  and z through STDP. Populations of neurons
and z through STDP. Populations of neurons  (
( ) on the first layer encode the values of input variables xi
. The population of neurons ζ on the third layer encodes the value of z. The hidden layer consists of populations of excitatory neurons
) on the first layer encode the values of input variables xi
. The population of neurons ζ on the third layer encodes the value of z. The hidden layer consists of populations of excitatory neurons  (I = 1, . . . , L) that are subject to lateral inhibition. STDP applied to the weights
(I = 1, . . . , L) that are subject to lateral inhibition. STDP applied to the weights  of synaptic connections from the first layer to the neurons α
on the hidden layer enables the network to approximate for any network input x through the firing probability of neurons on the third layer the distribution of values z that were associated with x in previously processed examples
of synaptic connections from the first layer to the neurons α
on the hidden layer enables the network to approximate for any network input x through the firing probability of neurons on the third layer the distribution of values z that were associated with x in previously processed examples  .
.
We assume that each of the random variables x and z is represented by a population of neurons (“population coding”), with each value of the variable encoded by a separate neuron in the population, as indicated at the top of Figure 2 for the variables xi
, and at the bottom for the variable z. The firing of a particular neuron χim
in the population coding of variable xi
encodes the fact that xi
assumes the value m in the currently presented example. Similarly the firing of neuron ζl
in the population ζ
for the variable z encodes the value l of this variable (Fig. 2). Finally, we assume that an example  is presented to this three-layer network during learning in the following manner: Those neurons in the first layer that represent the given values of the variables x are made to fire at a high rate, whereas the other neurons in the first layer are inhibited and kept silent. In addition, if variable z has value l in this example, all hidden neurons outside the corresponding subpopulation
is presented to this three-layer network during learning in the following manner: Those neurons in the first layer that represent the given values of the variables x are made to fire at a high rate, whereas the other neurons in the first layer are inhibited and kept silent. In addition, if variable z has value l in this example, all hidden neurons outside the corresponding subpopulation  are inhibited, so that they cannot fire (actually, it would suffice to block STDP for these neurons). An alternative view is that only a selected subset of neurons is disinhibited. New experimental data (for review, see Caroni, 2015) suggest that in fact inhibition of synaptic plasticity (especially via Somatostatin-positive neurons) and disinhibition via VIP interneurons (Letzkus et al., 2015) play an important role in the control of plasticity in cortical microcircuits.
are inhibited, so that they cannot fire (actually, it would suffice to block STDP for these neurons). An alternative view is that only a selected subset of neurons is disinhibited. New experimental data (for review, see Caroni, 2015) suggest that in fact inhibition of synaptic plasticity (especially via Somatostatin-positive neurons) and disinhibition via VIP interneurons (Letzkus et al., 2015) play an important role in the control of plasticity in cortical microcircuits.
When the network does not receive examples, the neurons in this network module fire according to the stochastic dynamics of the model, and no plasticity is assumed to occur. We present in Materials and Methods a rigorous proof that after learning the distribution of output values z for a given network input x approximates in this stochastic association module the conditional distribution  of the joint distribution
of the joint distribution  from which the values of z and x are drawn in the training examples. In fact, one can view this module from a theoretical perspective as an implicit generative model
from which the values of z and x are drawn in the training examples. In fact, one can view this module from a theoretical perspective as an implicit generative model  for the examples
for the examples  , and one can prove that the network module performs a stochastic search (stochastic online Expectation Maximization) that strives to minimize the Kullback–Leibler divergence
, and one can prove that the network module performs a stochastic search (stochastic online Expectation Maximization) that strives to minimize the Kullback–Leibler divergence  between the external distribution p* from which the examples are drawn and its internal model
between the external distribution p* from which the examples are drawn and its internal model  (see Materials and Methods, Theorem 1 and Theorem 1*). The implicit generative model of the module is encoded in the synaptic weights and biases of the α
neurons.
(see Materials and Methods, Theorem 1 and Theorem 1*). The implicit generative model of the module is encoded in the synaptic weights and biases of the α
neurons.
Because the learning module represents the full joint distribution  , not just the conditional distribution
, not just the conditional distribution  , it is the joint distribution that is considered to be the internal model of the learning module. This is more than just representing
, it is the joint distribution that is considered to be the internal model of the learning module. This is more than just representing  as the module also represents the distribution
as the module also represents the distribution  . The distribution
. The distribution  is represented in a sense that all probability values
is represented in a sense that all probability values  for each value of x can be calculated from the synaptic weights and biases of the α
neurons. This can be done by first calculating
for each value of x can be calculated from the synaptic weights and biases of the α
neurons. This can be done by first calculating  for each value of z based on the probabilistic model (see Materials and Methods), and then marginalizing out z. Another reason why
for each value of z based on the probabilistic model (see Materials and Methods), and then marginalizing out z. Another reason why  is considered as internal model is that the learning rules are based on minimizing the Kullback–Leibler divergence between the internally represented joint distribution
is considered as internal model is that the learning rules are based on minimizing the Kullback–Leibler divergence between the internally represented joint distribution  and the target distribution p
*(x, z) of the examples. In other words, the module implements generative model learning. The conditional distribution becomes important after learning, when the module performs its function realized through the firing of the output neurons that approximates p*
and the target distribution p
*(x, z) of the examples. In other words, the module implements generative model learning. The conditional distribution becomes important after learning, when the module performs its function realized through the firing of the output neurons that approximates p* ). This functional property of the learning module enables composing networks of modules that can learn larger distributions, as described in the section “Recursive combinations of the basic learning module enable efficient learning of complex distributions from examples.”
). This functional property of the learning module enables composing networks of modules that can learn larger distributions, as described in the section “Recursive combinations of the basic learning module enable efficient learning of complex distributions from examples.”
One may wonder why a two-layer network would not suffice for learning such stochastic associations between random variables x and z. The simplest approach would be a model without hidden neurons, where the strengths of the synaptic connections between the neurons in the population codes for x and z encode the probability that a vector x is encountered in conjunction with a particular value of z. But this approach would restrict very much the types of internal models p(x, z) that the network could learn. In particular, it could not handle a situation where the distribution p *(x, z = l) is multimodal, ie, when there are multiple modes in the distribution of x that are likely to occur in conjunction with a specific value l of z. For example in Figure 3B for z = 2, the distribution p *(x, z = 2) has two modes, ie, x 1 = 1 can occur in combination with x 2 = 2, and x 1 = 2 in combination with x 2 = 1 (whereas the assignments where x 1 = x 2 do not occur). The reason for this restriction to unimodal distributions is that the neuron ζl that represents z = l in the population code for z would have to represent through the implicit generative model that is defined by the weights of afferent synapses and its excitability the marginal distribution p *(x, z = l). However, a single linear neuron can only represent one mode of a probability distribution of x. However if one considers more complex neuron models with nonlinear dendritic processing, they can in principle also represent multimodal distributions (Pecevski et al., 2011, their Figs. 4 and 5; Legenstein and Maass, 2011). Hence, with such more complex neuron models a more shallow learning network could potentially be used as a learning module in our architecture.

Learning results for Example 1. A, Structure of the learning module. There are two subpopulations  of hidden neurons that both receive inputs from the two populations on layer 1 that encode the input variables x
1 and x
2. Each subpopulation of hidden neurons projects to a different neuron in the population coding of the variable z on layer 3. B, Left, The target probability distribution
of hidden neurons that both receive inputs from the two populations on layer 1 that encode the input variables x
1 and x
2. Each subpopulation of hidden neurons projects to a different neuron in the population coding of the variable z on layer 3. B, Left, The target probability distribution  of the examples (grey bars) and the internal model
of the examples (grey bars) and the internal model  (blue bars) that is extracted from the examples by the hidden neurons. The learned probabilities match the target probabilities quite well. Right, The two mixture components
(blue bars) that is extracted from the examples by the hidden neurons. The learned probabilities match the target probabilities quite well. Right, The two mixture components  and
and  represented by the hidden neurons
represented by the hidden neurons  and
and  in the subpopulation
in the subpopulation  . Each has specialized to represent one of the two modes. The resulting internal model
. Each has specialized to represent one of the two modes. The resulting internal model  is a sum of these two mixture components. C, Same as the plots on the left in B, but for a larger network where four hidden neurons were used in each subpopulation
is a sum of these two mixture components. C, Same as the plots on the left in B, but for a larger network where four hidden neurons were used in each subpopulation  of hidden neurons. This larger size of the subpopulations is suggested by the network construction from Pecevski et al. (2011), because the vector x can assume four different values. However, a comparison with C shows that smaller subpopulations suffice here for good learning performance. D, Left, The target probabilities
of hidden neurons. This larger size of the subpopulations is suggested by the network construction from Pecevski et al. (2011), because the vector x can assume four different values. However, a comparison with C shows that smaller subpopulations suffice here for good learning performance. D, Left, The target probabilities  (grey bars) compared with the learned firing probabilities of the output neurons
(grey bars) compared with the learned firing probabilities of the output neurons  and ζ
2 that represent
and ζ
2 that represent  and
and  respectively. Right, The probability of firing in response to different inputs x for the two hidden neurons
respectively. Right, The probability of firing in response to different inputs x for the two hidden neurons  and
and  that drive
that drive  to fire. E, Same as the left plots in D, but for the larger network as in C. Again, one sees that fewer hidden neurons are needed here than in the construction of Pecevski et al. (2011). F, Firing activity of the hidden neurons and output neurons in the module in response to two different input patterns
to fire. E, Same as the left plots in D, but for the larger network as in C. Again, one sees that fewer hidden neurons are needed here than in the construction of Pecevski et al. (2011). F, Firing activity of the hidden neurons and output neurons in the module in response to two different input patterns  and
and  . The firing rates of
. The firing rates of  and
and  correspond to their probabilities of firing shown in D.
correspond to their probabilities of firing shown in D.
The three-layer circuit in Figure 2 can be viewed as a minimal model for allowing multimodal distributions of x to be associated with a value of z. In fact, if one allows sufficiently many hidden neurons α
, this representation becomes arbitrarily precise. These hidden neurons α
represent combinations of features represented through the neurons  that encode the variables x. This mixed coding is reminiscent of experimental data on neurons in the cortex (Rigotti et al., 2013; Mante et al., 2013).
that encode the variables x. This mixed coding is reminiscent of experimental data on neurons in the cortex (Rigotti et al., 2013; Mante et al., 2013).
We exploit here a generic property of STDP in WTA circuits, that was made explicit by Nessler et al. (2013) and Habenschuss et al. (2013b): if the neurons in the populations for the variables xi are synaptically connected to a set of neurons α in a WTA circuit, and these synaptic connections are subject to STDP, then the neurons α learn automatically a multimodal internal model for the distribution of the variables x. The learned probabilistic model is a mixture of multinomials. More precisely, each WTA neuron α specializes to fire in response to input patterns from one mode of p*(x). This specialization is produced by the plasticity rules (Eqs. 1, 2), which, when a neuron fires in response to some input pattern, adapt the weights and biases of the neuron so that in the future it fires with higher probability in response to the same pattern. At the same time, the competition enforced by the lateral inhibition between the α neurons tends to prevent that multiple WTA neurons specialize on the same mode of p*(x).
This emergent property of STDP in WTA circuits was considered by Nessler et al. (2013) and Habenschuss et al. (2013b) in a setting where no association of x with other variables z needed to be learnt. In order to learn associations with z, we apply this mechanism in parallel for every possible value of z. In particular, we assume that in the population α
of WTA neurons there are disjoint subpopulations  for each possible value l of z. The subpopulation
for each possible value l of z. The subpopulation  projects to the ζl
neuron with strong synaptic weights so that a spike of a neuron in
projects to the ζl
neuron with strong synaptic weights so that a spike of a neuron in  causes also the neuron ζl
to fire (Fig. 2). As the WTA subcircuit
causes also the neuron ζl
to fire (Fig. 2). As the WTA subcircuit  is allowed to fire only for examples from p*
is allowed to fire only for examples from p* = l) it learns to approximate this distribution.
= l) it learns to approximate this distribution.
Intrinsic plasticity of the excitability of the hidden neurons  is also essential for successful learning. As they are not firing during a presentation of example
is also essential for successful learning. As they are not firing during a presentation of example  with z≠l, the only adaptation in them for such example is a decay of their intrinsic excitabilities (Eq. 3). This supports learning of a representation of the marginal probability p*(z = l) in the biases of the neurons in
with z≠l, the only adaptation in them for such example is a decay of their intrinsic excitabilities (Eq. 3). This supports learning of a representation of the marginal probability p*(z = l) in the biases of the neurons in  . Hence, the population
. Hence, the population  learns a probabilistic model
learns a probabilistic model  of the target probability distribution p*(x, z = l) = p*
of the target probability distribution p*(x, z = l) = p* = l)
p*(z = l). In this way all populations
= l)
p*(z = l). In this way all populations  together learn a generative model
together learn a generative model  for the joint distribution
for the joint distribution  of the presented examples.
of the presented examples.
Further details can be found in Materials and Methods, section “Theoretical properties of the basic learning module (stochastic association module) and its plasticity.”
Example 1: the learning module extracts complex stochastic associations from examples
We illustrate the inner workings of the learning module in an example where the task is to learn an internal model of an example target distribution p*(x
1, x
2, z) over binary RVs. This learning task is nontrivial since the distributions of values of x that are stochastically associated with the values z = 2 and z = 1 according to p* are multimodal (Fig. 3B, gray bars). After learning, the output neurons of the module should fire for input x according to the conditional probability p* . The structure of the network module is depicted in Figure 3A. It has two hidden neurons in the populations
. The structure of the network module is depicted in Figure 3A. It has two hidden neurons in the populations  and
and  , which learn the two modes of p*(x, z = 1) and the two modes of p*(x, z = 2), respectively (Fig. 3B). The learning period of the module lasted 1200 s of simulated biological time. During learning, examples from p*(x, z) were presented to the module for 100 ms each. After learning, each WTA subcircuit
, which learn the two modes of p*(x, z = 1) and the two modes of p*(x, z = 2), respectively (Fig. 3B). The learning period of the module lasted 1200 s of simulated biological time. During learning, examples from p*(x, z) were presented to the module for 100 ms each. After learning, each WTA subcircuit  had in fact acquired an approximation of the distribution p*(x, z = l), as can be seen in Figure 3B. The learning of the internal model in the WTA subcircuit
had in fact acquired an approximation of the distribution p*(x, z = l), as can be seen in Figure 3B. The learning of the internal model in the WTA subcircuit  is achieved through a process where each hidden neuron specializes to represent one of the two modes of p*(x, z = 2) that are shown in Figure 3B. For the subcircuit
is achieved through a process where each hidden neuron specializes to represent one of the two modes of p*(x, z = 2) that are shown in Figure 3B. For the subcircuit  the results are similar (not shown). The learning of an approximation to p*(x, z) as an internal model automatically produces an approximation of the conditional p*
the results are similar (not shown). The learning of an approximation to p*(x, z) as an internal model automatically produces an approximation of the conditional p* by the firing probabilities of the output neurons (Fig. 3D). A typical resulting firing pattern is shown in Figure 3F.
by the firing probabilities of the output neurons (Fig. 3D). A typical resulting firing pattern is shown in Figure 3F.
Recursive combinations of the basic learning module enable efficient learning of complex distributions from examples
The stochastic association module shown in Figures 2 and 3 is self-consistent in the sense that the input variables xi are encoded through population coding in the same way as the output variable z. Hence, one can recursively combine these modules so that the output population of one module becomes part of the input population of another module (Fig. 4). The resulting more complex network is then not only able to learn a single probabilistic association between RVs, but many such associations simultaneously. The basic learning modules form here not only chain connections, but typically also cycles, where the RV that is the output of the second module is simultaneously an input to the first module in the chain (like the variable yk in Fig. 4).
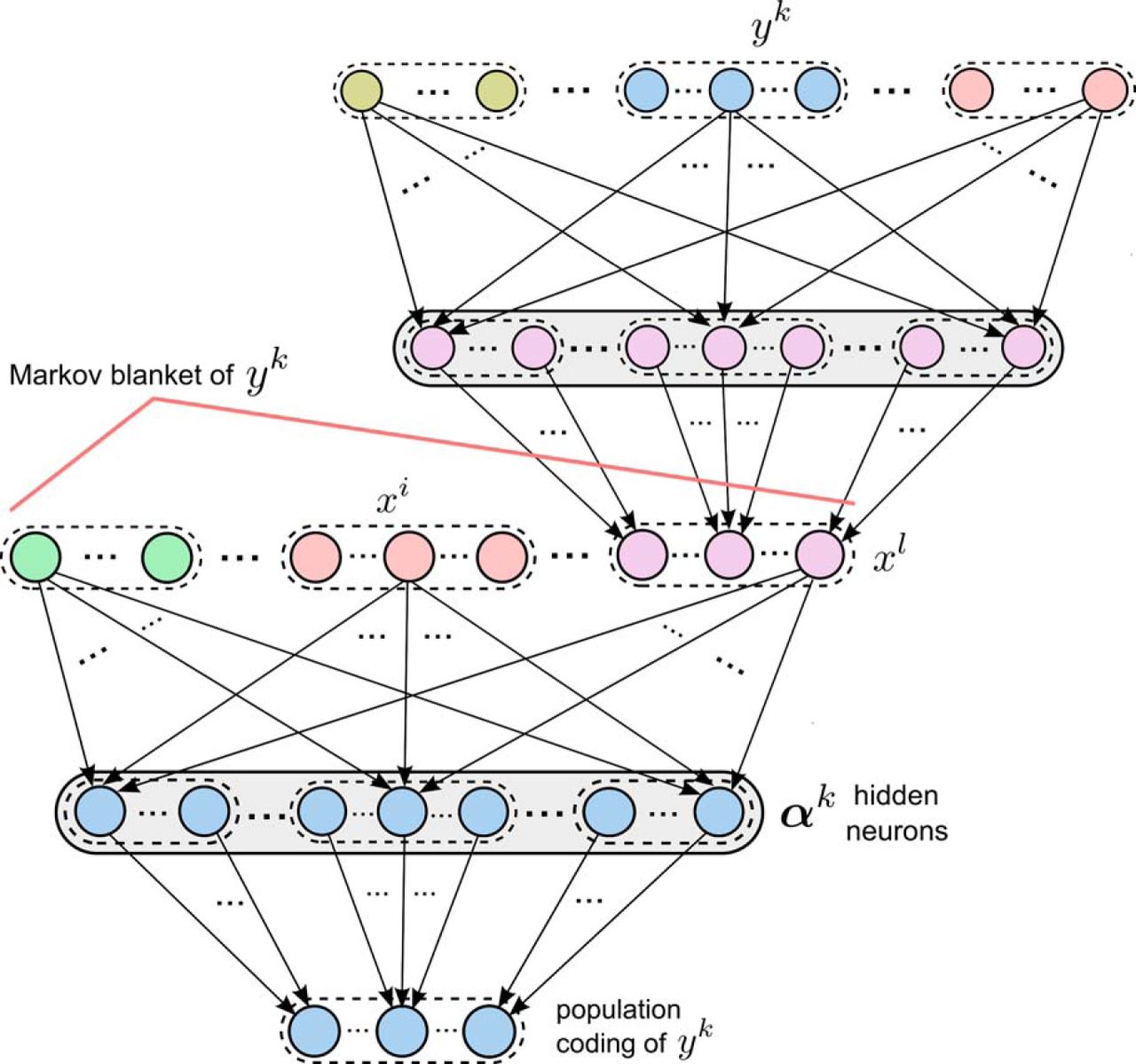
Recursive combination of learning modules. The learning module for the RV yk
at the bottom has the same structure as the modules shown in Figures 2 and 3. For learning complex distributions p* its input variables  form a Markov blanket of yk
. Each variable xi
is encoded by the same population coding as the output variables of learning modules, and can therefore be produced by the output of another learning module (as shown for the RV xl
). As here yk
is in the Markov blanket of xl
, yk
appears among the input variables of the upper module, and its corresponding input neurons are the same as the output neurons of the lower module.
form a Markov blanket of yk
. Each variable xi
is encoded by the same population coding as the output variables of learning modules, and can therefore be produced by the output of another learning module (as shown for the RV xl
). As here yk
is in the Markov blanket of xl
, yk
appears among the input variables of the upper module, and its corresponding input neurons are the same as the output neurons of the lower module.
Elementary results from probability theory imply that such recursive combinations of probabilistic associations between RVs have a very powerful, in fact universal, representation capability: the dependency structure of every probability distribution p* over discrete RVs can be represented as a network of probabilistic associations between each of the RVs yk and a subset of the other RVs (Bishop, 2006). More precisely, in the representation of an arbitrary distribution p* one has a subnetwork (module) for each RV yk of p* that has yk as output variable and the random variables in the Markov blanket y B ( k ) of yk as input variables. The Markov blanket defines a set of random variables so that conditioned on their values, yk becomes independent from all remaining variables. For example, if p* can be represented by a Bayesian network, it suffices to include in y B ( k ) the parents of yk together with the children of yk , and their coparents.
Whereas the classical results from probability theory only imply that one can represent any distribution p* over discrete RVs as such recursive network of probabilistic associations, it was shown in (Buesing et al., 2011; Pecevski et al., 2011) that any such target distribution p* can also be represented as stationary distribution of a network of spiking neurons, if suitable parameters (weights and biases) are programmed into the network. One only needs to assume that every spike of a neuron that participates in the population coding for one of the RVs yk
sets the value of yk
for a time period of length τ (= standard length of an EPSP) equal to the value encoded by this neuron. Then a suitably programmed network N
of spiking neurons that results from recursive combinations of the basic module from Figure 2 can represent any distribution p* through its spontaneous firing activity (provided that each module for a RV yk
represents  as described above). If one decodes the current firing activity in the network N
at any time t by setting each RV yk
to that value that is indicated by the most recent firing of a neuron in the population code for yk
, the resulting distribution of value assignments to the RVs y
1, . . . , yK
of p* over time is exactly the one given by p*. In other words, p* is the stationary distribution of the Markov chain that is defined by this network N
of stochastically firing neurons. On the side, we would like to point out that this holds only after some initial “burn-in” phase, during which the distribution of network states becomes independent of the initial network state (Habenschuss et al., 2013a).
as described above). If one decodes the current firing activity in the network N
at any time t by setting each RV yk
to that value that is indicated by the most recent firing of a neuron in the population code for yk
, the resulting distribution of value assignments to the RVs y
1, . . . , yK
of p* over time is exactly the one given by p*. In other words, p* is the stationary distribution of the Markov chain that is defined by this network N
of stochastically firing neurons. On the side, we would like to point out that this holds only after some initial “burn-in” phase, during which the distribution of network states becomes independent of the initial network state (Habenschuss et al., 2013a).
We now show (Fig. 5) that if one takes the previously analyzed learning capability of the basic network modules  into account, the composed spiking network N
learns from examples
into account, the composed spiking network N
learns from examples  of value assignments to
of value assignments to  drawn from p* values θ
for its weights and biases that provide an approximation
drawn from p* values θ
for its weights and biases that provide an approximation  of p
*(y). This approximation
of p
*(y). This approximation  is represented by the network in the form of its stationary distribution of network states that result from its spontaneous firing activity. In order to achieve that, one just needs to allow each learning module
is represented by the network in the form of its stationary distribution of network states that result from its spontaneous firing activity. In order to achieve that, one just needs to allow each learning module  to learn in parallel from those components of the example
to learn in parallel from those components of the example  that concern the random variables that it represents in the previously described manner. More precisely, each module
that concern the random variables that it represents in the previously described manner. More precisely, each module  receives the components
receives the components  of each example
of each example  that is presented to the network (for n = 1, 2, . . . ). The network N
learns an approximation of p* from examples
that is presented to the network (for n = 1, 2, . . . ). The network N
learns an approximation of p* from examples  without any additional computational overhead or teaching signals. Each subnetwork
without any additional computational overhead or teaching signals. Each subnetwork  learns through STDP and intrinsic plasticity an internal model
learns through STDP and intrinsic plasticity an internal model  of the marginal distribution
of the marginal distribution  , as described in the preceding section.
, as described in the preceding section.

Schematic description of the learning approach. Sequence of examples  drawn from the target distribution
drawn from the target distribution  are presented to the neural network N
. The neural network is composed of learning modules
are presented to the neural network N
. The neural network is composed of learning modules  , one for each RV yk
.
, one for each RV yk
.  learns from the components
learns from the components  of examples
of examples  an approximation
an approximation  of
of  as indicated in Figures 2 and 3. The theory based on EM ensures that the total network N
learns in this way an approximation
as indicated in Figures 2 and 3. The theory based on EM ensures that the total network N
learns in this way an approximation  of
of  .
.
One can rigorously prove that the sum over k of Kullback–Leibler divergences between the marginal distributions  and the learnt internal models
and the learnt internal models  converges through these adaptive processes to a local minimum (see Materials and Methods, Theorem 2). In this sense the spiking network N
learns an approximation
converges through these adaptive processes to a local minimum (see Materials and Methods, Theorem 2). In this sense the spiking network N
learns an approximation  of the distribution
of the distribution  .
.
As long as the RVs y are not split into inputs and outputs, this learning process is a typical example of unsupervised learning (see the definition in standard textbooks, such as Bishop (2006); Murphy, (2012); Haykin (2009)). Characteristic for unsupervised learning is that learning progress is measured in terms of the deviation between the learnt distribution  (= learnt internal model) and the distribution
(= learnt internal model) and the distribution  from which the examples are generated. One also refers to this type of learning as density estimation.
from which the examples are generated. One also refers to this type of learning as density estimation.
Unsupervised learning has previously already been studied in a large number of artificial neural networks models: from Boltzmann machines (Ackley et al., 1985), neural belief networks (Neal, 1992), up to deep learning networks (Salakhutdinov and Hinton, 2012; Bengio et al., 2015). One major motivation of this work has been to discover learning principles of the brain, based on the argument that supervision for learning is rare in the brain. Our learning model provides a complementary approach, with the main difference being that it is based on networks of spiking neurons, rather than artificial neural networks, and that it uses STDP as primary plasticity mechanism. A major difference between the learning process in Boltzmann machines and our model is that our model does not require separate sleep phases. Its learning process is more similar to parameter learning in Bayesian networks (Koller and Friedman, 2009, Chapter 17). There the learning process also amounts to learning for each RV separately and in parallel from examples the conditional probability table for each RV, conditioned on the values of its parents. Such learning of a conditional probability table is analogous to the learning in a stochastic association module, except that such association module considers all RVs in the Markov blanket of a given RV, rather than just its parents. However, our learning approach is more general than parameter learning in Bayesian networks insofar, as it also encompasses aspects of structure learning (Koller and Friedman, 2009, Chapter 18), see section below, “Small numbers of hidden neurons in the learning modules often suffice.”
Like other generative models for unsupervised learning, our model also aims at extracting underlying structure in the training examples (Hinton et al., 1995), so that it can even generate fake examples that share the discovered underlying structure (Fig. 7). On the level of higher cortical areas such unsupervised learning could detect relationships between different types of features (Figs. 6–9), between object representations in different sensory modalities, or how an action modifies the environment.
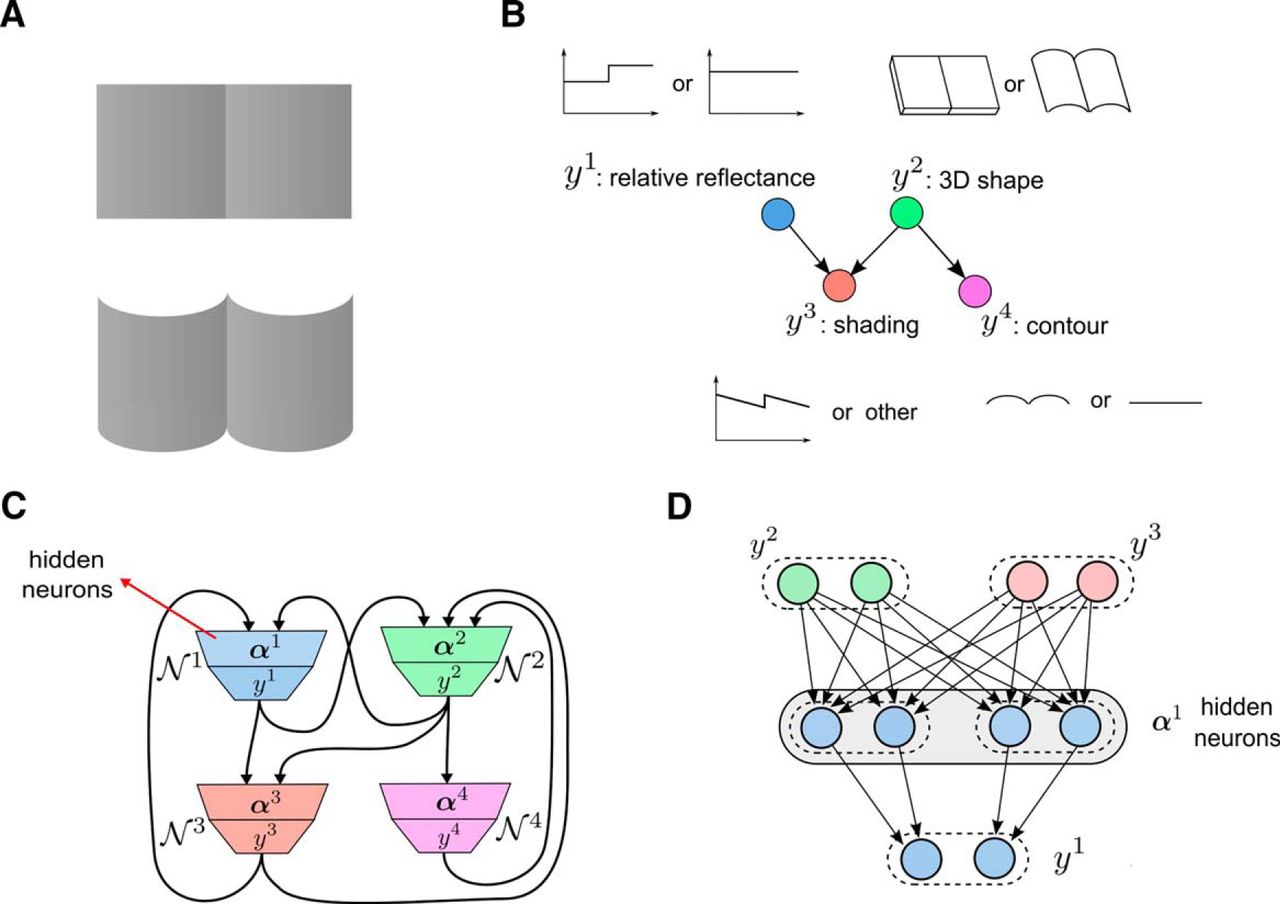
Description of the perceptual explaining away example. A, The two visual stimuli used in the experiment from Knill and Kersten (1991). Both surfaces, top and bottom, have identical shading profiles in the horizontal direction. Nevertheless, subjects perceive that the reflectances of the two halves of the bottom panel are the same, whereas they perceive the left half of the top panel as being darker than the right half. The different contours of the two panels suggest different 3D shapes (flat vs cylindrical), which influences subjects’ perception of the reflectance of the two halves of each surface. B, The “explaining away” Bayesian network proposed by Kersten and Yuille (2003) that models the effect from A. It consists of four RVs y
1, y
2, y
3, and y
4. The relative reflectance y
1 of the surfaces can have two values: y
1 = 2 for different and y
1 = 1 for the same reflectance of the two parts of the surface. The 3D shape of the surfaces (y
2) is either cylindrical (y
2 = 2) or rectangular (y
2 = 1). The relative reflectance and the 3D shape are direct causes of the shading or the luminance change of the surfaces (y
3), which can have the profile like in the bottom part of B (y
3 = 2) or a different one (y
3 = 1). The 3D shape of an object causes different 2D contours (y
4), which can be either straight (y
4 = 1) or curved (y
4 = 2). The observed variables are the contour (y
4) and the shading (y
3) of the surfaces. Subjects infer the value of the relative reflectance (y
1) and the 3D shape (y
2) based on these observed cues. C, The structure of the neural network N
that corresponds to the Bayesian network in B. For each RV yk
in the Bayesian network there is a learning module  composed of a population of neurons that outputs yk
in population coding, and a population of hidden neurons
composed of a population of neurons that outputs yk
in population coding, and a population of hidden neurons  . The learning modules are interconnected according to the Markov blankets of the RVs in the Bayesian network as indicated in Figure 4. For example, the RVs in the Markov blanket of y
1 are y
2 and y
3, and therefore the learning module
. The learning modules are interconnected according to the Markov blankets of the RVs in the Bayesian network as indicated in Figure 4. For example, the RVs in the Markov blanket of y
1 are y
2 and y
3, and therefore the learning module  receives connections from
receives connections from  and
and  . D, Structure of the learning module
. D, Structure of the learning module  for the RV y
1 in the neural network in C.
for the RV y
1 in the neural network in C.
In contrast to the previously mentioned paradigms for unsupervised learning in neural networks, and similar to parameter learning in Bayesian networks, the architecture that we are proposing has a clear modular structure (Fig. 5). It consists of stereotypical network motifs  that each try to determine for one of the RVs yk
to what extent values for yk
can be predicted from the values of other RVs (more precisely: the RVs in its Markov blanket
that each try to determine for one of the RVs yk
to what extent values for yk
can be predicted from the values of other RVs (more precisely: the RVs in its Markov blanket  ). As soon as this prediction becomes better than chance, the learning module
). As soon as this prediction becomes better than chance, the learning module  has discovered some underlying structure in the examples
has discovered some underlying structure in the examples  . One curious feature of this local prediction learning is that the learning process looks from the perspective of the learning module
. One curious feature of this local prediction learning is that the learning process looks from the perspective of the learning module  like supervised learning, because
like supervised learning, because  is the prediction target for input
is the prediction target for input  to this module, and both
to this module, and both  and
and  are part of a training example
are part of a training example  . This holds in spite of the fact that the whole examples
. This holds in spite of the fact that the whole examples  are in general presented to the network without any supervision, ie, without any associated target output. This feature of the learning process is shared with parameter learning in Bayesian networks, where the learning of a conditional probability table for a RV y may look locally like supervised learning, because both the values of its parent nodes and the value of y are extracted from each training example.
are in general presented to the network without any supervision, ie, without any associated target output. This feature of the learning process is shared with parameter learning in Bayesian networks, where the learning of a conditional probability table for a RV y may look locally like supervised learning, because both the values of its parent nodes and the value of y are extracted from each training example.
Boltzmann machines and probabilistic graphical models such as Bayesian networks that are usually trained through unsupervised learning can, however, also be used for supervised learning (Hinton et al., 2006). In that case, the RVs y are split into two subsets yI
and yO
, ie, the target output  is combined with the vector
is combined with the vector  to form the examples
to form the examples  used for training. The goal is to learn a mapping from yI
to yO
, ie, to learn the distribution
used for training. The goal is to learn a mapping from yI
to yO
, ie, to learn the distribution  . We consider here the general case where the mapping from inputs to target values is stochastic, either due to present noise in the target values or their inherent stochastic relation to the inputs. Typical classification problems where the mapping is assumed to be a deterministic function represent a special case of the stochastic formulation. For example, for supervised learning of image categorization in Boltzmann machines one simply adds the target category like an additional feature to the feature vector of an image. The learning process remains exactly the same (ie, unsupervised learning from examples
. We consider here the general case where the mapping from inputs to target values is stochastic, either due to present noise in the target values or their inherent stochastic relation to the inputs. Typical classification problems where the mapping is assumed to be a deterministic function represent a special case of the stochastic formulation. For example, for supervised learning of image categorization in Boltzmann machines one simply adds the target category like an additional feature to the feature vector of an image. The learning process remains exactly the same (ie, unsupervised learning from examples  ), and for learning one does not have to tell the network which variables are inputs and which are outputs. The only difference is that after learning only the components yI
of new test examples are provided and the network has to produce a guess for values of the components yO
. The same principle applies to the neural network in our approach: If y is partitioned into yI
and yO
it can learn the input–output mapping by learning an internal model of the full joint distribution
), and for learning one does not have to tell the network which variables are inputs and which are outputs. The only difference is that after learning only the components yI
of new test examples are provided and the network has to produce a guess for values of the components yO
. The same principle applies to the neural network in our approach: If y is partitioned into yI
and yO
it can learn the input–output mapping by learning an internal model of the full joint distribution  of the examples. After the learning process has finished, the network can estimate the probabilities of the target values
of the examples. After the learning process has finished, the network can estimate the probabilities of the target values  given a particular input yI
. However, note that, as it learns the joint distribution, the network can additionally also answer any other probabilistic inference queries based on the probability distribution p* of the examples (see section “Flexible retrieval of learnt statistical information through probabilistic inference”).
given a particular input yI
. However, note that, as it learns the joint distribution, the network can additionally also answer any other probabilistic inference queries based on the probability distribution p* of the examples (see section “Flexible retrieval of learnt statistical information through probabilistic inference”).
Classical learning of associative memory (like in a Hopfield network) also appears as a special case of the type of network learning that we are investigating: If  is nonzero only for some set
is nonzero only for some set  of M memory items. For these memory items the network learns then input completion. Such input completion can be accomplished through the learnt internal model
of M memory items. For these memory items the network learns then input completion. Such input completion can be accomplished through the learnt internal model  in our framework: If one clamps some of the neurons to the values of some given incomplete pattern
in our framework: If one clamps some of the neurons to the values of some given incomplete pattern  , and lets the other neurons fire according to the stochastic dynamics of this internal model. But note that the learning task of our model is more demanding than classical learning of associative memory, because it also has to learn the probability distribution (frequency) of the patterns
, and lets the other neurons fire according to the stochastic dynamics of this internal model. But note that the learning task of our model is more demanding than classical learning of associative memory, because it also has to learn the probability distribution (frequency) of the patterns  .
.
The underlying learning theory for our model (based on Expectation Maximization) does not guarantee that the internal model  converges to the target distribution
converges to the target distribution  . Rather, as in all known cases of nontrivial unsupervised learning and self-organization it can only guarantee that a local optimum is achieved (which cannot get worse if learning continues). However, even this weak form of a theoretical guarantee is actually quite rare in the literature on neural network learning via STDP. Most known successful methods for unsupervised learning or self-organization in machine learning are supported theoretically in the same weak manner via Expectation Maximization. However many of these methods work very well in practice. The learning speed and quality depend for the learning framework that we have introduced on the nature of the target distribution p*. We are demonstrating in Example 2 that this learning scheme works well for an example of p* where it is well known that humans are able to learn a good approximation of probabilistic inference for p*.
. Rather, as in all known cases of nontrivial unsupervised learning and self-organization it can only guarantee that a local optimum is achieved (which cannot get worse if learning continues). However, even this weak form of a theoretical guarantee is actually quite rare in the literature on neural network learning via STDP. Most known successful methods for unsupervised learning or self-organization in machine learning are supported theoretically in the same weak manner via Expectation Maximization. However many of these methods work very well in practice. The learning speed and quality depend for the learning framework that we have introduced on the nature of the target distribution p*. We are demonstrating in Example 2 that this learning scheme works well for an example of p* where it is well known that humans are able to learn a good approximation of probabilistic inference for p*.
Flexible retrieval of learnt statistical information through probabilistic inference
After learning, the network N
from Figure 5 has an approximation  to
to  as its stationary distribution. This holds under the convention that the firing of a neuron that represents a specific value l of a variable yk
sets this variable to value l for a duration τ equal to the duration of a generic EPSP. The learned distribution is manifested in the spontaneous activity of the network, ie, when no neurons in the network are clamped. Information can be extracted from this learnt internal model
as its stationary distribution. This holds under the convention that the firing of a neuron that represents a specific value l of a variable yk
sets this variable to value l for a duration τ equal to the duration of a generic EPSP. The learned distribution is manifested in the spontaneous activity of the network, ie, when no neurons in the network are clamped. Information can be extracted from this learnt internal model  through probabilistic inference via neural sampling. This type of information retrieval goes far beyond input completion, which is the only form of information retrieval in classical neural network models for memory. In particular, after inserting evidence into N
by exciting or inhibiting some of the neurons that represent a subset ye
of the variables, the spiking activity of the rest of the network generates according to Pecevski et al. (2011) samples from the conditional posterior distribution
through probabilistic inference via neural sampling. This type of information retrieval goes far beyond input completion, which is the only form of information retrieval in classical neural network models for memory. In particular, after inserting evidence into N
by exciting or inhibiting some of the neurons that represent a subset ye
of the variables, the spiking activity of the rest of the network generates according to Pecevski et al. (2011) samples from the conditional posterior distribution  , where ys
is the subset of variables that are not in ye
. Furthermore, the posterior marginal probabilities
, where ys
is the subset of variables that are not in ye
. Furthermore, the posterior marginal probabilities  of the variables yk
in ys
can be read out from the resulting firing rates of the neurons that represent these variables. Thus, information gathered from the examples
of the variables yk
in ys
can be read out from the resulting firing rates of the neurons that represent these variables. Thus, information gathered from the examples  that had been presented to the network N
(Fig. 5) can be extracted from this network in very flexible ways through probabilistic inference. This will be demonstrated for an example in Figures 6–9. In particular, the network can produce estimates of posterior marginal probabilities of the type indicated through examples in the Significance Statement. Note that these marginal probabilities, that are represented by the firing rates of corresponding neurons in N
, integrate automatically information from many modes of the learnt approximation
that had been presented to the network N
(Fig. 5) can be extracted from this network in very flexible ways through probabilistic inference. This will be demonstrated for an example in Figures 6–9. In particular, the network can produce estimates of posterior marginal probabilities of the type indicated through examples in the Significance Statement. Note that these marginal probabilities, that are represented by the firing rates of corresponding neurons in N
, integrate automatically information from many modes of the learnt approximation  to p*. Hence, if these modes represent individual memory items of a memory model, the network N
can combine information from many different memory items (episodes), also in ways that could not be anticipated during learning.
to p*. Hence, if these modes represent individual memory items of a memory model, the network N
can combine information from many different memory items (episodes), also in ways that could not be anticipated during learning.
Small numbers of hidden neurons in the learning modules often suffice
The structure of the network N
in Figure 5 is very similar to the structure of a constructed network of spiking neurons that directly mimics a representation of p* by a Bayesian network according to Pecevski et al. (2011). However, there the number of hidden neurons  for a random variable yk
was required to be exponentially large in the number of variables in the Markov blanket of yk
. In contrast, in the learning approach of this article, one can employ in principle any number, also a very small number, of hidden neurons in
for a random variable yk
was required to be exponentially large in the number of variables in the Markov blanket of yk
. In contrast, in the learning approach of this article, one can employ in principle any number, also a very small number, of hidden neurons in  . The described learning approach will approximate the marginal distribution of p* over yk
and the Markov blanket of yk
with a mixture distribution whose number of modes is determined by the chosen number of hidden neurons in
. The described learning approach will approximate the marginal distribution of p* over yk
and the Markov blanket of yk
with a mixture distribution whose number of modes is determined by the chosen number of hidden neurons in  . For example, in Example 1 we had chosen just two hidden neurons in α
for each of the two possible values of z, instead of two times four that were used in the construction of Pecevski et al. (2011) for representing all four possible assignments of values to the inputs x of a module. But as the comparison of Figure 3, B and C (and of D and E) shows, the network with the smaller number of hidden neurons α
works in this case about as well as the larger network. This effect is predicted from general results in learning theory: a learning network with fewer parameters sacrifices representation power, but gains generalization capability. Furthermore, naturally occurring distributions can often be approximated quite well by mixture distributions with a relatively small number of components (modes). This suggests that real world distributions p* of examples can often be learnt by relatively small networks N
. An ideal scenario from a biological perspective would be one where a population of hidden neurons in N
can become larger if the size provides insufficient resolution or prediction capability for the examples that it receives.
. For example, in Example 1 we had chosen just two hidden neurons in α
for each of the two possible values of z, instead of two times four that were used in the construction of Pecevski et al. (2011) for representing all four possible assignments of values to the inputs x of a module. But as the comparison of Figure 3, B and C (and of D and E) shows, the network with the smaller number of hidden neurons α
works in this case about as well as the larger network. This effect is predicted from general results in learning theory: a learning network with fewer parameters sacrifices representation power, but gains generalization capability. Furthermore, naturally occurring distributions can often be approximated quite well by mixture distributions with a relatively small number of components (modes). This suggests that real world distributions p* of examples can often be learnt by relatively small networks N
. An ideal scenario from a biological perspective would be one where a population of hidden neurons in N
can become larger if the size provides insufficient resolution or prediction capability for the examples that it receives.
Note that with this approach a spiking network N
can in principle learn an approximation of a given distribution p* even without prior information on the dependency structure among RVs of p*. One can set up the network N
so that each module  extracts the probabilistic association between RV yk
and all other RVs
extracts the probabilistic association between RV yk
and all other RVs  (ie, replacing y
B
(
k
) by all RVs other than yk
). The size (ie, number of hidden neurons α
; Fig. 2) of
(ie, replacing y
B
(
k
) by all RVs other than yk
). The size (ie, number of hidden neurons α
; Fig. 2) of  determines the quality of the resulting learnt approximation of
determines the quality of the resulting learnt approximation of  . Whereas a good approximation can only be theoretically guaranteed if the number of hidden neurons in
. Whereas a good approximation can only be theoretically guaranteed if the number of hidden neurons in  is exponential in the number K of RVs of p*, acceptable results may emerge with drastically fewer hidden neurons, provided that their number is in the same range as the sum of the number of main modes of the distributions
is exponential in the number K of RVs of p*, acceptable results may emerge with drastically fewer hidden neurons, provided that their number is in the same range as the sum of the number of main modes of the distributions  for different values l (Fig. 3 provides an illustration).
for different values l (Fig. 3 provides an illustration).
Example 2: autonomous learning of explaining away in perceptual inference
We demonstrate learning in recursive combinations of the basic learning module for a concrete example with four modules (Fig. 6C). We apply it to the task of learning a complex distribution p* that represents a standard example for explaining away in visual perception. The famous experiment of (Knill and Kersten, 1991), depicted in Figure 6, had first demonstrated that nontrivial inference is involved in visual perception. A subsequent study (Kersten and Yuille, 2003) proposed that this perceptual effect can be understood as “explaining away” in probabilistic inference, and a Bayesian network with 4 RVs,  (Fig. 6B) was introduced to demonstrate this. The probability distribution of the Bayesian network is
(Fig. 6B) was introduced to demonstrate this. The probability distribution of the Bayesian network is  , and the inference task is to calculate the marginal posterior probability distributions
, and the inference task is to calculate the marginal posterior probability distributions  and
and  .
.
In the experiment of Knill and Kersten (1991), the demonstrated different perception of the shading in the two surfaces in Figure 6A (see legend for more details) can be explained by two different competing causes, either by different relative reflectance of the two abutting surfaces (y 1), or by their cylindrical 3D shape (y 2). An observed curved contour of the surfaces is a cue that increases the probability of a cylindrical 3D shape. Because a cylindrical 3D shape alone is enough to explain the shading, it reduces the probability that the relative reflectance is different. Hence, one of the competing causes, the cylindrical 3D shape, “explains away” the other possible cause, the different reflectance of the surfaces. In the other case, when a flat contour is observed as an additional cue, this increases the probability of a rectangular 3D shape. As a rectangular 3D shape cannot explain the observed shading, the probability of the second possible cause for the shading, the different reflectance is increased. This type of explaining away in probabilistic inference can only occur for distributions p* that have higher-order interactions between three or more RVs, like between the two competing causes and the observed shading in this example.
We show that the underlying distribution p* can be learnt (approximately) from examples for this visual perception task, and that the network N which learns this approximation learns simultaneously to deal with the explaining away effect as an emergent phenomenon.
The structure of the neural network N
suitable for learning this target probability distribution p* is given in Figure 6C. It consists of four interconnected learning modules, where the connections between the learning modules reflect the dependencies between the RVs in the Bayesian network in Figure 6B. Additionally, the structure of one of the learning modules, the learning module  for the RV y
1, is given in Figure 6D in detail. Each subgroup
for the RV y
1, is given in Figure 6D in detail. Each subgroup  of hidden neurons has two neurons. This number of hidden neurons is smaller than the number of hidden neurons in the exact neural implementations of this Bayesian network by Pecevski et al. (2011), (their Implementation 2), equal to the total number of assignments of values to the RVs in the Markov blanket, which in this case is four. But we show that the smaller neural network can nevertheless learn the distributions
of hidden neurons has two neurons. This number of hidden neurons is smaller than the number of hidden neurons in the exact neural implementations of this Bayesian network by Pecevski et al. (2011), (their Implementation 2), equal to the total number of assignments of values to the RVs in the Markov blanket, which in this case is four. But we show that the smaller neural network can nevertheless learn the distributions  , because these distributions do not have more than two modes. In fact, we use here just two hidden neurons in the subgroups
, because these distributions do not have more than two modes. In fact, we use here just two hidden neurons in the subgroups  of all learning modules, also for the learning module
of all learning modules, also for the learning module  , where the total number of assignments of values to the RVs in the Markov blanket is 8. As we will see in the results, two hidden neurons in the learning module
, where the total number of assignments of values to the RVs in the Markov blanket is 8. As we will see in the results, two hidden neurons in the learning module  are enough to learn a good approximation of
are enough to learn a good approximation of  .
.
We performed computer simulations of learning with this network, where examples drawn from the target probability distribution p* were presented to the network successively during learning. The distribution p* was defined according to Table 4 in Materials and Methods in order to capture the visual perception scenario of Figure 6 in a qualitative manner. The learning phase took 1200 s of simulated biological time, and each example was presented for a time period of 100 ms. The weights and biases of the neurons were randomly initialized before learning.
We first analyzed the stationary distribution of network states in the network N
from Figure 6C after learning. Figure 7A shows that the network switches spontaneously between different network states, and occasionally remains longer in one of the network states that have high probability under the stationary distribution (Fig. 6B). One can relate the firing activity of this network N
to an approximation  of the target distribution
of the target distribution  by assuming in the usual manner (Berkes et al., 2011; Buesing et al., 2011) that the firing of a neuron in the population code for variable yk
sets the value of this variable for a time period of length τ to the value encoded by this neuron. The distribution over 4 binary random variables
by assuming in the usual manner (Berkes et al., 2011; Buesing et al., 2011) that the firing of a neuron in the population code for variable yk
sets the value of this variable for a time period of length τ to the value encoded by this neuron. The distribution over 4 binary random variables  obtained in this way from the spontaneous firing of the network N
is shown in Figure 7B and compared with the target distribution p*.
obtained in this way from the spontaneous firing of the network N
is shown in Figure 7B and compared with the target distribution p*.

Analysis of the stationary distribution of network states of the network from Figure 6C after learning. A, Random sample of spontaneous activity of the network (without any external input). The network switches stochastically between different network states (some of which are labeled by colors), in a manner that is qualitatively similar to experimental data from networks of neurons in the cortex (Abeles et al., 1995; Jones et al., 2007). The spike trains of neurons that encode a problem variable yk
through population coding are underlined by blue lines. Spike trains immediately above are from the hidden neurons  that drive this neuron to fire (as in Fig. 2). B, Frequency of network states that encode particular assignments to the problem variables yk
(shown on the x-axis) resulting from the learned stationary distribution (spontaneous activity)
that drive this neuron to fire (as in Fig. 2). B, Frequency of network states that encode particular assignments to the problem variables yk
(shown on the x-axis) resulting from the learned stationary distribution (spontaneous activity)  of the network are shown as green bars. The coloring of the network states labels is the same as for corresponding network states in A. Black bars indicate the probabilities of the same value assignments under the distribution p* that had produced the examples for learning.
of the network are shown as green bars. The coloring of the network states labels is the same as for corresponding network states in A. Black bars indicate the probabilities of the same value assignments under the distribution p* that had produced the examples for learning.
In Figure 8A we examined how the learning in the modules progresses in time. In each of the four learning modules in the network (one for each problem variable yk
; Figs. 5, 6C) the Kullback–Leibler (KL) divergence between the marginal target distribution  that it learns to approximate and its internal model
that it learns to approximate and its internal model  decreases and stabilizes to a local minimum after about 300 s. The same is true for the sum of all KL divergences of the modules (Fig. 8B). As a result, the difference between the model distribution
decreases and stabilizes to a local minimum after about 300 s. The same is true for the sum of all KL divergences of the modules (Fig. 8B). As a result, the difference between the model distribution  of the network and the full target distribution
of the network and the full target distribution  also decreases, as shown in Figure 8C. This is because after learning a good internal model of the marginal target distributions
also decreases, as shown in Figure 8C. This is because after learning a good internal model of the marginal target distributions  , the firing probability of the output neurons of the learning modules approximate well the conditionals
, the firing probability of the output neurons of the learning modules approximate well the conditionals  of p*, as shown in Figure 8D, which according to the theory leads to a good approximation of p* by the network.
of p*, as shown in Figure 8D, which according to the theory leads to a good approximation of p* by the network.

Performance of the recursive combination of learning modules from Figure 6C in learning the perceptual inference task of Knill and Kersten (1991) from examples. A, Evolution of the KL divergence between the target distribution  of the examples (denoted in the plot as
of the examples (denoted in the plot as  ) and the distribution of the internal model
) and the distribution of the internal model  during learning, for each of the learning modules
during learning, for each of the learning modules  in the network (
in the network ( ). B, Evolution of the sum of the KL divergences shown in A. C, Evolution of the KL divergence between the internal model distribution
). B, Evolution of the sum of the KL divergences shown in A. C, Evolution of the KL divergence between the internal model distribution  represented by the whole network and the target distribution
represented by the whole network and the target distribution  of the examples during learning. D, The plots show the target conditional distributions
of the examples during learning. D, The plots show the target conditional distributions  (black bars), and the learned conditional distributions
(black bars), and the learned conditional distributions  (green bars), for each problem variable yk
. The bit string labels on the x-axis denote the assignment of values to the problem variables on which each distribution is conditioned.
(green bars), for each problem variable yk
. The bit string labels on the x-axis denote the assignment of values to the problem variables on which each distribution is conditioned.
The PSPs and STDP curves in the simulated network have a more biological smoother alpha shape, which differs from the rectangular shape used in the theory. This can introduce minor deviations of the learning convergence from the theoretically optimal one, as for example the slight increase of the KL divergence in Figure 8C in the second half of the learning process.
This network N
can extract the information that it has acquired from the examples in a very flexible manner through probabilistic inference. For example, if evidence e is entered for some of the problem variables  (by inducing corresponding neurons in their population codes to fire at high rates) the conditional marginal probabilities of other variables yi
can be read off from the firing rates of neurons that represent yi
through population coding. In particular, we demonstrate in Figure 9 that the network N
has acquired autonomously from examples the capability to carry out nontrivial probabilistic inference that involves explaining away (ie, higher order dependencies among random variables).
(by inducing corresponding neurons in their population codes to fire at high rates) the conditional marginal probabilities of other variables yi
can be read off from the firing rates of neurons that represent yi
through population coding. In particular, we demonstrate in Figure 9 that the network N
has acquired autonomously from examples the capability to carry out nontrivial probabilistic inference that involves explaining away (ie, higher order dependencies among random variables).

Demonstration that the network N
from Figure 6C has learnt explaining away. A, B, Results of probabilistic inference (estimate of posterior marginal probabilities) by the network through observation of the firing rates of neurons that encode y
1 and y
2 (whereas other neurons are “clamped” to encode the evidence e) are shown as green bars. The results are from a single run with duration 400 ms per evidence value. Black bars indicate corresponding values for p* (“ground truth”). The network estimates the probabilities  (indicating different relative reflectance according to Figure 6B) and
(indicating different relative reflectance according to Figure 6B) and  (indicating a cylindrical 3D shape) for two different evidence values e = (y
3, y
4) through sampling from its stationary distribution of network states. In the first inference we assume e = (2, 2) (indicating an observation with discontinuous shading of the object and curved contour), and in the second e = (2, 1) (observation of discontinuous shading and straight contour). C, The spiking activity of the network N
during online inference of hidden causes, where the evidence e was switched after t = 3s (red vertical line) from e = (2, 2) to e = (2, 1). Spike trains of neurons from population codes for problem variables yk
are underlined by blue lines (as in Figure 7A). D, Firing rates (estimated with a sliding alpha kernel
(indicating a cylindrical 3D shape) for two different evidence values e = (y
3, y
4) through sampling from its stationary distribution of network states. In the first inference we assume e = (2, 2) (indicating an observation with discontinuous shading of the object and curved contour), and in the second e = (2, 1) (observation of discontinuous shading and straight contour). C, The spiking activity of the network N
during online inference of hidden causes, where the evidence e was switched after t = 3s (red vertical line) from e = (2, 2) to e = (2, 1). Spike trains of neurons from population codes for problem variables yk
are underlined by blue lines (as in Figure 7A). D, Firing rates (estimated with a sliding alpha kernel  , t = 0.1 s) of the neurons encoding y
1 = 2 (different relative reflectance, dashed line) and y
2 = 2 (cylindrical 3D shape) during the inference simulation run shown in C. The “explaining away” effect is clearly visible from the complementary evolution of the firing rates of the two neurons that represent the two potential hidden causes “cylindrical 3D shape” and “different relative reflectance.”
, t = 0.1 s) of the neurons encoding y
1 = 2 (different relative reflectance, dashed line) and y
2 = 2 (cylindrical 3D shape) during the inference simulation run shown in C. The “explaining away” effect is clearly visible from the complementary evolution of the firing rates of the two neurons that represent the two potential hidden causes “cylindrical 3D shape” and “different relative reflectance.”
Finally, we would like to point out that our approach is not restricted to Bayesian networks; it can be applied to any type of graphical models, eg, also to Markov random fields and factor graphs. The network connectivity is determined by the Markov blankets of the random variables, which can easily be read out from the graph structure of any graphical model.
Materials and Methods
We first present a rigorous learning theory that supports the learning results that are presented. After that, we provide details to the computer simulations.
Theoretical properties of the basic learning module (stochastic association module) and its plasticity
In this section, we give additional details about the structure of the module, the firing of the output neurons and the learning procedure. In particular, the subsequent subsection titled “Implicitly represented generative model” defines the probabilistic model  represented in the module. After that, in the two subsections “Firing probability of the output neurons resulting from the internal generative model” and “Deriving the probability distribution of the firing of the neurons α
” the firing of the output and the alpha neurons in the module is expressed through the represented probabilistic model. The last subsection “The plasticity rules minimize the KL divergence through Expectation Maximization” continues with the explanation how the plasticity rules implement learning of the stochastic associations between the variables x and z through EM.
represented in the module. After that, in the two subsections “Firing probability of the output neurons resulting from the internal generative model” and “Deriving the probability distribution of the firing of the neurons α
” the firing of the output and the alpha neurons in the module is expressed through the represented probabilistic model. The last subsection “The plasticity rules minimize the KL divergence through Expectation Maximization” continues with the explanation how the plasticity rules implement learning of the stochastic associations between the variables x and z through EM.
The neurons α
in the learning module are interconnected through inhibitory interneurons (data not shown in Fig. 2) that enforce strong lateral inhibition between them. The role of the lateral inhibition is to ensure that if one of the α
neurons fires at time t, no other neuron in α
will fire within the interval (t, t + τ). Each neuron in population α
receives input synaptic connections from all input neurons χ
such that the firing of the population  encodes the value of the input variable xi
(Fig. 2). For each non-zero value of the input variable xi
= m there is a dedicated neuron
encodes the value of the input variable xi
(Fig. 2). For each non-zero value of the input variable xi
= m there is a dedicated neuron  , and if
, and if  fired in the time period (t – τ, t], the value of xi
at time t is xi
= m. The firing in the population
fired in the time period (t – τ, t], the value of xi
at time t is xi
= m. The firing in the population  is such that no two neurons fire in the time interval (t – τ, t], ie, after a spike there is no spiking period of duration τ. If there is no spike in the interval (t – τ, t], then the value of xi
is 0.
is such that no two neurons fire in the time interval (t – τ, t], ie, after a spike there is no spiking period of duration τ. If there is no spike in the interval (t – τ, t], then the value of xi
is 0.
All neurons in the population  connect to their corresponding output neuron ζl
. These synaptic connections are not subject to synaptic plasticity and have a fixed strong efficacy. The strong weights of these synapses achieve that whenever any of the neurons in
connect to their corresponding output neuron ζl
. These synaptic connections are not subject to synaptic plasticity and have a fixed strong efficacy. The strong weights of these synapses achieve that whenever any of the neurons in  fires, it drives the output neuron ζl
to fire. The output neurons fire only if they receive input spikes, otherwise they remain silent. Thus, the spikes that the neuron ζl
emits can be seen as a union of all spikes of the hidden neurons in the group
fires, it drives the output neuron ζl
to fire. The output neurons fire only if they receive input spikes, otherwise they remain silent. Thus, the spikes that the neuron ζl
emits can be seen as a union of all spikes of the hidden neurons in the group  .
.
One can give an analytical description for the firing probability density of the output neuron ζl
according to the model. To do that, first we need to introduce some notation. With  we denote the efficacy of the synaptic connection from the input neuron χim
to the neuron
we denote the efficacy of the synaptic connection from the input neuron χim
to the neuron  from the group
from the group  . For the bias (intrinsic excitability) of the neuron
. For the bias (intrinsic excitability) of the neuron  , we write
, we write  . We also introduce, for simplicity, binary RVs xim
corresponding to each neuron χim
. The binary RV xim
assumes value 1 at time t if the current value of the RV xi
is equal to m, and 0 otherwise. The current value of xim
at time t can be determined just from the spikes of the neuron χim
, ie, it is 1 if χim
fired within the time interval [t, t – τ], and 0 otherwise. With this notation, we can describe the firing probability density of ζl
at time t by:
. We also introduce, for simplicity, binary RVs xim
corresponding to each neuron χim
. The binary RV xim
assumes value 1 at time t if the current value of the RV xi
is equal to m, and 0 otherwise. The current value of xim
at time t can be determined just from the spikes of the neuron χim
, ie, it is 1 if χim
fired within the time interval [t, t – τ], and 0 otherwise. With this notation, we can describe the firing probability density of ζl
at time t by: (4)where
(4)where  is the membrane potential of neuron
is the membrane potential of neuron  , Jl
is the number of neurons in the subpopulation
, Jl
is the number of neurons in the subpopulation  , and M(xi
) denotes the maximum integer value that xi
can assume. The firing probability density of the output neuron ζl
is equal to the sum of the firing probability densities of all neurons in the subpopulation
, and M(xi
) denotes the maximum integer value that xi
can assume. The firing probability density of the output neuron ζl
is equal to the sum of the firing probability densities of all neurons in the subpopulation  , which follows from the specific connectivity structure in the learning module. The sums with the indices i and m iterate over all input neurons χim
.
, which follows from the specific connectivity structure in the learning module. The sums with the indices i and m iterate over all input neurons χim
.
During learning, we assume that examples  drawn from the joint probability distribution
drawn from the joint probability distribution  are presented to the WTA circuit in succession, one by one. In an example the variable z has an integer value from the set
are presented to the WTA circuit in succession, one by one. In an example the variable z has an integer value from the set  (M(z) denotes the maximum integer value that z can assume), and each of the variables xi
assumes a value from the set
(M(z) denotes the maximum integer value that z can assume), and each of the variables xi
assumes a value from the set  . Each example
. Each example  is presented for several tens or hundreds of milliseconds. During this time period, the input neurons fire according to the values of the input variables
is presented for several tens or hundreds of milliseconds. During this time period, the input neurons fire according to the values of the input variables  . In particular, if
. In particular, if  , then the input neuron χim
fires with a high firing rate, whereas all other input neurons in the population
, then the input neuron χim
fires with a high firing rate, whereas all other input neurons in the population  are silent. The value
are silent. The value  in the example is given to the network via inhibitory currents in a subset of the neurons α
. More precisely, if in the current example
in the example is given to the network via inhibitory currents in a subset of the neurons α
. More precisely, if in the current example  , then all neurons in α
that do not belong to
, then all neurons in α
that do not belong to  are inhibited with a strong negative external current which prevents them from firing. At the same time the neurons in the group
are inhibited with a strong negative external current which prevents them from firing. At the same time the neurons in the group  do not receive any external inhibitory currents and are free to fire according to their firing probabilities determined by their inputs. At the beginning of the learning process, it is assumed that the biases of the α
neurons have large values so that they fire with high firing rates regardless of what the presented input
do not receive any external inhibitory currents and are free to fire according to their firing probabilities determined by their inputs. At the beginning of the learning process, it is assumed that the biases of the α
neurons have large values so that they fire with high firing rates regardless of what the presented input  is.
is.
As stated above, in the presented examples during learning the variables z and xi
(i = 1, . . . , I) assume values from the sets  and
and  , respectively. These values could represent states of the external environment, internal beliefs or any other behavior related variable value. However, in the population coding of values of the variables z and xi
(i = 1, . . . , I) by their corresponding neuron populations in the learning module, the variables can have an additional value of zero. A neuron population that encodes a variable through population coding assigns value zero to this variable if none of the neurons fires for a period longer than τ. There is not a dedicated neuron whose firing signals a zero value, as is the case for the rest of the non-zero values of the variable. The assumed spike based encoding with a zero value is the same as in the neural sampling theory (Buesing et al., 2011; Pecevski et al., 2011). It defines a value for the variable at each moment in the continuous time dynamics of the neural network model.
, respectively. These values could represent states of the external environment, internal beliefs or any other behavior related variable value. However, in the population coding of values of the variables z and xi
(i = 1, . . . , I) by their corresponding neuron populations in the learning module, the variables can have an additional value of zero. A neuron population that encodes a variable through population coding assigns value zero to this variable if none of the neurons fires for a period longer than τ. There is not a dedicated neuron whose firing signals a zero value, as is the case for the rest of the non-zero values of the variable. The assumed spike based encoding with a zero value is the same as in the neural sampling theory (Buesing et al., 2011; Pecevski et al., 2011). It defines a value for the variable at each moment in the continuous time dynamics of the neural network model.
The zero values in the population coding of the learning module do not represent states of the external environment. The reason for this is that the learning module does not learn the probabilities  in its internal model where some of the variables z and xi
(i = 1, . . . , I) have zero value. These probabilities have very fixed small (close to zero) values (see section “Firing probability of the output neurons resulting from the internal generative model”). Therefore, it is assumed that the examples contain only the encoded variable values whose stochastic relations can be learnt by the learning module.
in its internal model where some of the variables z and xi
(i = 1, . . . , I) have zero value. These probabilities have very fixed small (close to zero) values (see section “Firing probability of the output neurons resulting from the internal generative model”). Therefore, it is assumed that the examples contain only the encoded variable values whose stochastic relations can be learnt by the learning module.
Implicitly represented generative model
The learning theory of the module is based on its internally represented generative model  , as it is discussed in Results, section “A network module for learning stochastic associations” (see also section “The plasticity rules minimize the KL divergence through Expectation Maximization”). In order to define the implicitly represented generative model, we first define an additional compound RV a
in form of a vector of binary RVs, that we will relate to the stochastic activity of the neurons in the population α
. More precisely, the RV a
is defined as a population code, represented as a set of binary RVs
, as it is discussed in Results, section “A network module for learning stochastic associations” (see also section “The plasticity rules minimize the KL divergence through Expectation Maximization”). In order to define the implicitly represented generative model, we first define an additional compound RV a
in form of a vector of binary RVs, that we will relate to the stochastic activity of the neurons in the population α
. More precisely, the RV a
is defined as a population code, represented as a set of binary RVs  , one for each neuron
, one for each neuron  . The generated values of
. The generated values of  over time during the activity of the WTA circuit are defined by the spiking of
over time during the activity of the WTA circuit are defined by the spiking of  in the same way as the spiking of the input neurons χ
define the values of x. The value of
in the same way as the spiking of the input neurons χ
define the values of x. The value of  , which does not have a corresponding neuron in the population α
, is defined as
, which does not have a corresponding neuron in the population α
, is defined as  . Note that as there can be no two neurons in α
spiking within the time window (t – τ, t) because of the lateral inhibition, it follows that the vector RV a
has a restricted domain of allowed values, consisting only of values where exactly one
. Note that as there can be no two neurons in α
spiking within the time window (t – τ, t) because of the lateral inhibition, it follows that the vector RV a
has a restricted domain of allowed values, consisting only of values where exactly one  is equal to 1, and the others are 0. The value of a
where only
is equal to 1, and the others are 0. The value of a
where only  and the rest are 0 will be denoted by
and the rest are 0 will be denoted by  .
.
Having defined a
, we can now write the parametrized form of the generative model as follows: (5)where
(5)where  is the normalization constant. In the sum over the indices i and m, the index i iterates through all input variables from x
1 to xI
. For each value of the index i, the index m iterates from 0 to M(xi
), ie, through the set of possible values of the RV xi
. In the two sums with the indices l and j, l iterates through all possible values of z from 0 to L, and j iterates from 1 to Jl
(note that J
0 = 1, as there is not a group of neurons in α
for l = 0, and hence only 1 parameter). The parameter vector θ
consists of all parameters
is the normalization constant. In the sum over the indices i and m, the index i iterates through all input variables from x
1 to xI
. For each value of the index i, the index m iterates from 0 to M(xi
), ie, through the set of possible values of the RV xi
. In the two sums with the indices l and j, l iterates through all possible values of z from 0 to L, and j iterates from 1 to Jl
(note that J
0 = 1, as there is not a group of neurons in α
for l = 0, and hence only 1 parameter). The parameter vector θ
consists of all parameters  and
and  which are encoded in the synaptic weights and biases of the alpha neurons. After learning, the marginal distribution
which are encoded in the synaptic weights and biases of the alpha neurons. After learning, the marginal distribution  of Equation 5 becomes an internal model of the distribution
of Equation 5 becomes an internal model of the distribution  of the presented examples. The probability
of the presented examples. The probability  in Equation 5 is not parametrized and specifies the deterministic relations between a
and z. It is defined as follows:
in Equation 5 is not parametrized and specifies the deterministic relations between a
and z. It is defined as follows:  if l1 = l2, and = 0 otherwise, for all
if l1 = l2, and = 0 otherwise, for all  , and all (l2, j) that are valid values of a
. These probability values express the fact that when the neuron
, and all (l2, j) that are valid values of a
. These probability values express the fact that when the neuron  fires and sets the value of a
to be (l, j), then this also uniquely determines z, ie, sets the value of z to z = l.
fires and sets the value of a
to be (l, j), then this also uniquely determines z, ie, sets the value of z to z = l.
A sufficient condition for having a normalization constant  are the following constraints on the parameters:
are the following constraints on the parameters: (6)
(6)
As we will see later, one property of the plasticity rules is that they move the parameter vector toward the region of the parameter space where these normalization constraints are approximately satisfied, ie, they try to keep the internal probabilistic model normalized. If one assumes that the normalization constant satisfies  , then the generative model in Equation 5 obtains the form:
, then the generative model in Equation 5 obtains the form: (7)
(7)
By marginalizing a
in the full generative model  , we obtain the marginal probability distribution
, we obtain the marginal probability distribution  , which has the form of a mixture of multinomials. The marginal probabilistic model
, which has the form of a mixture of multinomials. The marginal probabilistic model  models the probabilistic relations between the RV z, encoded by the firing of the output neurons, and the RVs x, which are encoded in the inputs. These relations are modeled through the vector of auxiliary RVs a
, which are also called hidden RVs. In the mixture model the conditional probabilities
models the probabilistic relations between the RV z, encoded by the firing of the output neurons, and the RVs x, which are encoded in the inputs. These relations are modeled through the vector of auxiliary RVs a
, which are also called hidden RVs. In the mixture model the conditional probabilities  and
and  for i = 1, . . . , I are the likelihoods, and
for i = 1, . . . , I are the likelihoods, and  is the prior.
is the prior.
It can be easily shown from Equation 5 that by assuming  , the likelihoods
, the likelihoods  for i = 1, . . . , I are:
for i = 1, . . . , I are: (8)
(8)
Similarly the priors are: (9)Hence, given that the normalization constraints in Equation 6 hold, the parameters
(9)Hence, given that the normalization constraints in Equation 6 hold, the parameters  are equal to the log of the conditional probabilities from the likelihood
are equal to the log of the conditional probabilities from the likelihood  , whereas
, whereas  represent the log probabilities of the prior
represent the log probabilities of the prior  .
.
For convenience, Table 1 lists the mathematical notation that is used in the definition of the learning module.
Mathematical symbols used in the definition of the learning module
Firing probability of the output neurons resulting from the internal generative model
Here we will express the firing probability density of the output neurons through the probabilistic model  . This will show that by learning the internal model
. This will show that by learning the internal model  of the target distribution
of the target distribution  , the output neurons actually learn to fire according to the conditional
, the output neurons actually learn to fire according to the conditional  . Thus, as discussed in Results, section “A network module for learning stochastic associations,” the module exhibits the learned stochastic associations between the variables z and x through the firing of its output neurons given input x. Furthermore, this particular form of firing enables to recurrently interconnect multiple modules in larger networks to learn more complex distributions. Networks of interconnected learning modules are presented in Results, section “Recursive combinations of the basic learning module enable efficient learning of complex distributions from examples,” and further discussed in Materials and Methods, section “Theoretical properties of networks of recursively interconnected basic learning modules.”
. Thus, as discussed in Results, section “A network module for learning stochastic associations,” the module exhibits the learned stochastic associations between the variables z and x through the firing of its output neurons given input x. Furthermore, this particular form of firing enables to recurrently interconnect multiple modules in larger networks to learn more complex distributions. Networks of interconnected learning modules are presented in Results, section “Recursive combinations of the basic learning module enable efficient learning of complex distributions from examples,” and further discussed in Materials and Methods, section “Theoretical properties of networks of recursively interconnected basic learning modules.”
As a prerequisite to the derivation, we first establish a relation between the parameters  and
and  of the probabilistic model
of the probabilistic model  , and the synaptic weights
, and the synaptic weights  and biases
and biases  of the neurons in α
. For the synaptic weights
of the neurons in α
. For the synaptic weights  we assume that they are equal to the corresponding parameters
we assume that they are equal to the corresponding parameters  shifted by a constant baseline value
shifted by a constant baseline value  . Similarly, the biases of the neurons α
represent linearly translated values of the parameters
. Similarly, the biases of the neurons α
represent linearly translated values of the parameters  , ie,
, ie,  . The relation is defined through the following equations:
. The relation is defined through the following equations: (10)
(10)
This entails that the modification of synaptic weights and biases via synaptic and intrinsic plasticity during learning results in adaptation of the parameters of the represented generative model. Not all parameters in the generative model are learned, however. We assume that the parameters: (11)that do not have a corresponding synaptic weight or a bias, have fixed values that are not subject to learning. In particular,
(11)that do not have a corresponding synaptic weight or a bias, have fixed values that are not subject to learning. In particular,  and
and  are assumed to have the following values:
are assumed to have the following values: (12)where V is a large positive constant. We assume that the constant V is large enough so that the probabilities
(12)where V is a large positive constant. We assume that the constant V is large enough so that the probabilities  where at least one of the variables z and xi
(for i = 1, . . . , I) has zero value are much smaller than the probabilities of value assignments where all variables have non-zero values (Eq. 5).
where at least one of the variables z and xi
(for i = 1, . . . , I) has zero value are much smaller than the probabilities of value assignments where all variables have non-zero values (Eq. 5).
The fixed parameters are all subsumed in the baseline values w– and b–:
 (13)
(13)
From this it follows that one can write the synaptic weights and the biases as: (14)
(14)
Hence, we have a one-to-one mapping between the synaptic weights and biases of the neurons α
, and the parameters in the generative model that are subject to adaptation during learning. Note that from Equations 12 and 13, it follows that: (15)
(15)
If we now substitute the synaptic weights and biases from Equation 10 in the expression for the firing probability density ρl
(t) of the output neuron ζl
from Equation 4, we obtain: (16)
(16)
In this expression, we can combine the two sums over the index i that iterates through 1, . . . , I (we do this both in the denominator and in the numerator), and by using the equality  (where xi
0 is a binary RV, such that xi
0 = 1 if and only if xi
= 0), we get the simplified form:
(where xi
0 is a binary RV, such that xi
0 = 1 if and only if xi
= 0), we get the simplified form: (17)where we write simply xim
instead of xim
(t), as we assume it is implicitly understood that it is a function of time. It is clear that the denominator is equal to
(17)where we write simply xim
instead of xim
(t), as we assume it is implicitly understood that it is a function of time. It is clear that the denominator is equal to  . In the numerator, we can rewrite the sum by iterating over values of the RV a
as:
. In the numerator, we can rewrite the sum by iterating over values of the RV a
as: (18)where the sum indexed by a
iterates over all possible values of the compound RV a
having only one
(18)where the sum indexed by a
iterates over all possible values of the compound RV a
having only one  and others equal to 0, and in both sums inside the exp function indexed by
and others equal to 0, and in both sums inside the exp function indexed by  and j, the index
and j, the index  iterates over all possible values of z which are
iterates over all possible values of z which are  , and j iterates from 1 to
, and j iterates from 1 to  . It is now easy to see that the numerator is equal to
. It is now easy to see that the numerator is equal to  , and finally we obtain:
, and finally we obtain: (19)
(19)
Thus, the firing probability of the output neuron l is proportional to  , and if the internal model
, and if the internal model  is close to
is close to  , it will be proportional to
, it will be proportional to  (as pointed out in Results, section “A network module for learning stochastic associations”). For how this result is used in the theory for networks of interconnected learning modules that learn to perform probabilistic inference in larger distributions see section “Theoretical properties of networks of recursively interconnected basic learning modules.”
(as pointed out in Results, section “A network module for learning stochastic associations”). For how this result is used in the theory for networks of interconnected learning modules that learn to perform probabilistic inference in larger distributions see section “Theoretical properties of networks of recursively interconnected basic learning modules.”
Deriving the probability distribution of the firing of the neurons α
We show in this subsection that the firing of the neurons α
in the WTA circuit during the presentation of an example  generates samples from the distribution
generates samples from the distribution  . This result is used in section “The plasticity rules minimize the KL divergence through Expectation Maximization,” where the link between the plasticity rules, the activity of the neurons, and different calculations of the EM algorithm are discussed. In particular, it is explained there that, as the RVs a
are the hidden variables in the probabilistic model, the samples generated by the activity of the α
neurons together with the presented examples, form samples from the complete data distribution, which represents the expectation step of the EM algorithm. The result is further used in the section “Proof that the plasticity rules minimize the objective function
. This result is used in section “The plasticity rules minimize the KL divergence through Expectation Maximization,” where the link between the plasticity rules, the activity of the neurons, and different calculations of the EM algorithm are discussed. In particular, it is explained there that, as the RVs a
are the hidden variables in the probabilistic model, the samples generated by the activity of the α
neurons together with the presented examples, form samples from the complete data distribution, which represents the expectation step of the EM algorithm. The result is further used in the section “Proof that the plasticity rules minimize the objective function  through Expectation Maximization” in that the proof is based on analyzing mean weight updates of the plasticity rules over the complete data distribution.
through Expectation Maximization” in that the proof is based on analyzing mean weight updates of the plasticity rules over the complete data distribution.
During the presentation of a single example, in the periods when it is not inhibited by the lateral inhibition due to a spike by another neuron in α
, the firing probability density of each neuron  in α
ideally remains constant over time. Let us denote the stationary distribution of its associated RV
in α
ideally remains constant over time. Let us denote the stationary distribution of its associated RV  during the presentation of the example
during the presentation of the example  with
with  . We will also here use the assumption that the total firing rate of the
. We will also here use the assumption that the total firing rate of the  neurons is very high upon presentation of an example with
neurons is very high upon presentation of an example with  irrespective of what the input
irrespective of what the input  is. That this assumption is true can be seen from the following. As we stated previously, we assume that the initial values of the biases of the α
neurons are high. This implies that in the beginning of learning, for each presented example there will be active α
neurons that fire in response to the example. In addition, as b– has a large negative value (Eqs. 13, 15), it follows that the plasticity rule for the biases defined in Equations 2 and 3 will drive and stabilize the biases of the active α
neurons toward very large values. Thus, when an example with
is. That this assumption is true can be seen from the following. As we stated previously, we assume that the initial values of the biases of the α
neurons are high. This implies that in the beginning of learning, for each presented example there will be active α
neurons that fire in response to the example. In addition, as b– has a large negative value (Eqs. 13, 15), it follows that the plasticity rule for the biases defined in Equations 2 and 3 will drive and stabilize the biases of the active α
neurons toward very large values. Thus, when an example with  is presented, there will be always a subset of the neurons in α
that have high firing rates. Consequently, during the presentation of the example almost all the time there will be a neuron in
is presented, there will be always a subset of the neurons in α
that have high firing rates. Consequently, during the presentation of the example almost all the time there will be a neuron in  active and
active and  .
.
If we use the fact that  for
for  we can write:
we can write: (20)and equal to 0 otherwise. Here
(20)and equal to 0 otherwise. Here  denotes the firing probability density of
denotes the firing probability density of  , which is constant during the presentation of the example. If we substitute now the firing probability density in Equation 20 with:
, which is constant during the presentation of the example. If we substitute now the firing probability density in Equation 20 with: (21)
(21)
and additionally substitute the synaptic weights and biases with their related model parameters according to Equation 10, we get: (22)if
(22)if  and 0 otherwise. Then, if we use the definition of the generative model in Equation 5, we can write both the numerator and denominator as:
and 0 otherwise. Then, if we use the definition of the generative model in Equation 5, we can write both the numerator and denominator as: (23)
(23)
By multiplying now both the numerator and denominator by  and by using the fact that:
and by using the fact that: (24)
(24)
we finally arrive at: (25)
(25)
Hence, the neurons α
sample from  . As we pointed out at the beginning, this derivation is an important step in the proof that the plasticity rules implement the Expectation Maximization algorithm (see next subsection).
. As we pointed out at the beginning, this derivation is an important step in the proof that the plasticity rules implement the Expectation Maximization algorithm (see next subsection).
The plasticity rules minimize the KL divergence through Expectation Maximization
Here we further discuss the key property of the learning module pointed out in Results, section “A network module for learning stochastic associations,” that the plasticity rules modify the synaptic weights and biases in a way that minimizes the KL divergence between the full joint distribution of the generative model  and the corresponding target joint distribution
and the corresponding target joint distribution  . We denote the KL divergence between
. We denote the KL divergence between  and
and  as the objective function
as the objective function  ie,
ie, (26)
(26)
By using Equation 26, the key property of the learning module can be reformulated in form of the following theorem:
Theorem 1. The synaptic and intrinsic plasticity rules introduced in Equations 1, 2, and 3 change the parameters θ
so that they always converge to a local minimum of  subject to the normalization constraints (Eq. 6).
subject to the normalization constraints (Eq. 6).
The complete proof of the theorem is given in the next section “Proof that the plasticity rules minimize the objective function  through Expectation Maximization.” In this section we discuss the approach and the main steps of the proof, and we also describe how the convergence is carried out through the EM algorithm, ie, how the firing of the neurons and the synaptic weight updates by the plasticity rules implement different steps of EM. The complete details to the EM implementation can be found in the section “Proof that the plasticity rules minimize the objective function
through Expectation Maximization.” In this section we discuss the approach and the main steps of the proof, and we also describe how the convergence is carried out through the EM algorithm, ie, how the firing of the neurons and the synaptic weight updates by the plasticity rules implement different steps of EM. The complete details to the EM implementation can be found in the section “Proof that the plasticity rules minimize the objective function  through Expectation Maximization.”
through Expectation Maximization.”
The proof of Theorem 1 uses results from the Robbins–Monro methods for stochastic approximation (Kushner and Yin, 2003). What is shown in the proof is that first, STDP and intrinsic plasticity drive the parameters θ
toward satisfying the normalization constraints in Equation 6. As a second step, it is shown that given that θ
satisfy the normalization constraints, then the mean update of the parameters averaged over many presented examples is in the direction of the negative gradient of the objective function  . From these two intermediate steps, it follows that the parameters converge to a local minimum of
. From these two intermediate steps, it follows that the parameters converge to a local minimum of  under the normalization constraints.
under the normalization constraints.
By reducing the KL divergence between  and
and  , the module also aims to approximate the target conditional
, the module also aims to approximate the target conditional  by its internal model conditional
by its internal model conditional  that defines the firing of the output neurons. In particular, the objective function
that defines the firing of the output neurons. In particular, the objective function  is an upper bound of the function
is an upper bound of the function (27)which is the mean KL divergence between the target conditional and the model conditional, averaged over the distribution p*(x) of the inputs. This is easy to see from the equality:
(27)which is the mean KL divergence between the target conditional and the model conditional, averaged over the distribution p*(x) of the inputs. This is easy to see from the equality: (28)
(28)
Thus, EM aims to reduce the measure of how much the two conditionals differ  through minimizing its upper bound
through minimizing its upper bound  . If the upper bound during learning decreases, this does not always mean
. If the upper bound during learning decreases, this does not always mean  will decrease as well. Nevertheless, if the upper bound
will decrease as well. Nevertheless, if the upper bound  converged during learning to a certain small value C, then after learning
converged during learning to a certain small value C, then after learning  . And if C is small enough so that
. And if C is small enough so that  is a good approximation of
is a good approximation of  , in such a way the minimization of the upper bound would lead to good learning of the conditional. Furthermore, in the simulation experiments we showed that the learning based on minimizing the upper bound
, in such a way the minimization of the upper bound would lead to good learning of the conditional. Furthermore, in the simulation experiments we showed that the learning based on minimizing the upper bound  works well.
works well.
The update of the synaptic weights and the biases of the neurons in the WTA circuit can be understood as performing an online stochastic approximation of the EM algorithm. The EM algorithm is an iterative optimization algorithm that finds a local minimum of  indirectly through another function called the complete data log-likelihood. In order to establish the link with the neural network learning, we will consider a stochastic version of the EM algorithm (Wei and Tanner, 1990; Jank, 2006), that we describe in the following. We will also assume the more common version used in the literature where we have a finite sequence of examples
indirectly through another function called the complete data log-likelihood. In order to establish the link with the neural network learning, we will consider a stochastic version of the EM algorithm (Wei and Tanner, 1990; Jank, 2006), that we describe in the following. We will also assume the more common version used in the literature where we have a finite sequence of examples  for n = 1, . . . , N, instead of an infinite sequence drawn from
for n = 1, . . . , N, instead of an infinite sequence drawn from  . In the case of a finite sequence, the target distribution
. In the case of a finite sequence, the target distribution  is defined as the histogram of all examples. The main idea in EM is that we can substitute the original learning objective: to update the mixture generative model
is defined as the histogram of all examples. The main idea in EM is that we can substitute the original learning objective: to update the mixture generative model  so that it gets close to
so that it gets close to  by another learning objective: to update the full (complete data) generative model
by another learning objective: to update the full (complete data) generative model  (together with the hidden RVs a
) to get closer to the complete data target distribution:
(together with the hidden RVs a
) to get closer to the complete data target distribution: (29)
(29)
As there are not any complete data samples to learn the generative model  , but just incomplete data examples for the RVs x, z, in stochastic EM one completes the data samples by generating sample values for the hidden RVs a
from the generative model itself, ie, through the conditional distribution
, but just incomplete data examples for the RVs x, z, in stochastic EM one completes the data samples by generating sample values for the hidden RVs a
from the generative model itself, ie, through the conditional distribution  . This is done for all examples
. This is done for all examples  for n = 1, . . . , N. Then one updates the parameters so that the likelihood that the complete data examples were generated by the complete data generative model
for n = 1, . . . , N. Then one updates the parameters so that the likelihood that the complete data examples were generated by the complete data generative model  is increased. The completion of the data samples is called the “expectation” step, whereas the update of the parameters of the complete data generative model to increase the likelihood of the complete data examples is called the “maximization” step. The EM optimization is performed iteratively, where in each iteration one repeats these two steps. We can link the above two steps in the EM algorithm to concrete mechanisms in the dynamics of the WTA circuit during learning. Specifically, the expectation step is implemented through the firing of spikes by the neurons α
during the presentation of the data examples
is increased. The completion of the data samples is called the “expectation” step, whereas the update of the parameters of the complete data generative model to increase the likelihood of the complete data examples is called the “maximization” step. The EM optimization is performed iteratively, where in each iteration one repeats these two steps. We can link the above two steps in the EM algorithm to concrete mechanisms in the dynamics of the WTA circuit during learning. Specifically, the expectation step is implemented through the firing of spikes by the neurons α
during the presentation of the data examples  . Indeed, the firing of α
generates samples from the conditional distribution
. Indeed, the firing of α
generates samples from the conditional distribution  (see section “Deriving the probability distribution of the firing of the neurons α
”). The presented data examples together with the generated samples by the neurons α
form complete data samples from p* in Equation 29. The plasticity rules update the synaptic weights and biases exactly based on these complete data samples encoded in the spikes. Furthermore, given that the normalization constraints hold, the mean update of the parameters over the infinite sequence of examples (where the same finite sequence is repeated in succession infinitely) is in the direction of the gradient of the complete data log-likelihood (for details see section “Proof that the plasticity rules minimize the objective function
(see section “Deriving the probability distribution of the firing of the neurons α
”). The presented data examples together with the generated samples by the neurons α
form complete data samples from p* in Equation 29. The plasticity rules update the synaptic weights and biases exactly based on these complete data samples encoded in the spikes. Furthermore, given that the normalization constraints hold, the mean update of the parameters over the infinite sequence of examples (where the same finite sequence is repeated in succession infinitely) is in the direction of the gradient of the complete data log-likelihood (for details see section “Proof that the plasticity rules minimize the objective function  through Expectation Maximization”). In view of this established link between the offline mean update of the weights and the EM algorithm, we see that the online plasticity rules in the neural network implement an online stochastic approximation of the EM algorithm in the spirit of Monte Carlo EM (Wei and Tanner, 1990; Jank, 2006).
through Expectation Maximization”). In view of this established link between the offline mean update of the weights and the EM algorithm, we see that the online plasticity rules in the neural network implement an online stochastic approximation of the EM algorithm in the spirit of Monte Carlo EM (Wei and Tanner, 1990; Jank, 2006).
During learning of the distribution  by the WTA circuit
by the WTA circuit  , the neurons in
, the neurons in  self-organize so that each of them specializes to fire in response to one cluster of similar, frequently occurring input patterns. In the probability distribution
self-organize so that each of them specializes to fire in response to one cluster of similar, frequently occurring input patterns. In the probability distribution  , this cluster corresponds to one mode of the distribution. A mode of the distribution can be described as a region of high probability in the probability space, surrounded by regions of low probability. The theoretical basis of the learning strategy via EM proves that the plasticity rules change the synaptic weights and biases to reduce the difference between the distribution of the inputs
, this cluster corresponds to one mode of the distribution. A mode of the distribution can be described as a region of high probability in the probability space, surrounded by regions of low probability. The theoretical basis of the learning strategy via EM proves that the plasticity rules change the synaptic weights and biases to reduce the difference between the distribution of the inputs  and the represented generative model
and the represented generative model  . At the end, the learning process yields a mixture distribution where each neuron in
. At the end, the learning process yields a mixture distribution where each neuron in  represents one mixture component in the form of the unimodal distribution
represents one mixture component in the form of the unimodal distribution  centered at one of the clusters of input patterns. The full generative model
centered at one of the clusters of input patterns. The full generative model  is then retrieved as a sum of the unimodal distributions. The unimodal mixture component is implicitly represented in the weights and the bias of the corresponding neuron, where the vector of synaptic weights of the neuron actually represents the center of the mixture component, ie, the location in the input pattern space where its mode peaks with maximum probability.
is then retrieved as a sum of the unimodal distributions. The unimodal mixture component is implicitly represented in the weights and the bias of the corresponding neuron, where the vector of synaptic weights of the neuron actually represents the center of the mixture component, ie, the location in the input pattern space where its mode peaks with maximum probability.
Proof that the plasticity rules minimize the objective function  through Expectation Maximization
through Expectation Maximization

We will give in this subsection a proof of Theorem 1 from the previous subsection “The plasticity rules minimize the KL divergence through Expectation Maximization.” The theorem captures the main property of the learning module discussed in Results, section “A network module for learning stochastic associations,” ie, that the plasticity rules install in the module an internal representation of the stochastic associations between the variables x and z in the presented examples.
Before we present the main part of the proof, we first introduce some needed definitions and derivations.
Definitions and assumptions
According to the learning procedure, independent and identically distributed examples  drawn from the target probability distribution are presented to the learning module one by one, each presented for a certain period of time ΔtE
. The learning procedure was explained in section “Theoretical properties of the basic learning module (stochastic association module) and its plasticity.” The time interval ΔtE
for the presentation of the examples should be several times larger than the duration of the PSPs τ. The reason for this is that at the beginning of a time period ΔtE
when a new example
drawn from the target probability distribution are presented to the learning module one by one, each presented for a certain period of time ΔtE
. The learning procedure was explained in section “Theoretical properties of the basic learning module (stochastic association module) and its plasticity.” The time interval ΔtE
for the presentation of the examples should be several times larger than the duration of the PSPs τ. The reason for this is that at the beginning of a time period ΔtE
when a new example  is presented to the module, the values of the RVs x determined by the firing of the input neurons χ
do not immediately change to the new example. Additionally, the neurons α
do not immediately start to sample from the new conditional distribution
is presented to the module, the values of the RVs x determined by the firing of the input neurons χ
do not immediately change to the new example. Additionally, the neurons α
do not immediately start to sample from the new conditional distribution  . There can be residual active EPSPs at the synaptic inputs connecting from the input neurons that encode the values
. There can be residual active EPSPs at the synaptic inputs connecting from the input neurons that encode the values  from the previous time period ΔtE
. Similarly, there can be residual EPSPs from active neurons in α
that prevent the other α
neurons to immediately start sampling correctly from the new conditional distributions
from the previous time period ΔtE
. Similarly, there can be residual EPSPs from active neurons in α
that prevent the other α
neurons to immediately start sampling correctly from the new conditional distributions  . Therefore, for a time period of duration of one EPSP τ at the beginning of the presentation of a new example, the update of the synaptic weights and biases might be incorrect. Nevertheless, if τ is several times smaller than ΔtE
, this incorrect contribution to the learned weight (or bias) update should be insignificant.
. Therefore, for a time period of duration of one EPSP τ at the beginning of the presentation of a new example, the update of the synaptic weights and biases might be incorrect. Nevertheless, if τ is several times smaller than ΔtE
, this incorrect contribution to the learned weight (or bias) update should be insignificant.
As ΔtE
is larger than τ, this means that for each example  the WTA circuit generates several samples from the conditional
the WTA circuit generates several samples from the conditional  as the neurons α
spike several times during ΔtE
(see section “Deriving the probability distribution of the firing of the neurons α
”). For simplicity of notation and formulation, in the convergence proof we will assume that for each
as the neurons α
spike several times during ΔtE
(see section “Deriving the probability distribution of the firing of the neurons α
”). For simplicity of notation and formulation, in the convergence proof we will assume that for each  exactly one sample
exactly one sample  from
from  is generated. The convergence proof can be easily extended for the more general case when several samples are generated from
is generated. The convergence proof can be easily extended for the more general case when several samples are generated from  . Given this assumption, the presented data example
. Given this assumption, the presented data example  together with the generated sample
together with the generated sample  by the neurons α
represent one complete data example
by the neurons α
represent one complete data example  drawn from the complete data distribution
drawn from the complete data distribution  .
.
If with  we denote the parameter values before applying the learning rule for the n-th example, and with
we denote the parameter values before applying the learning rule for the n-th example, and with  we denote the values after the application of the learning rule, then:
we denote the values after the application of the learning rule, then: (30)where η(n) is the learning rate used in the n-th iteration,
(30)where η(n) is the learning rate used in the n-th iteration,  is the update according to the learning rules defined in Equations 1, 2, and 3 (for easier reference, the synaptic and intrinsic plasticity rules are also given in Table 2), and
is the update according to the learning rules defined in Equations 1, 2, and 3 (for easier reference, the synaptic and intrinsic plasticity rules are also given in Table 2), and  is a function that clips the parameter values within the intervals
is a function that clips the parameter values within the intervals  and
and  . The set of values θ
that are within these intervals we will denote with
. The set of values θ
that are within these intervals we will denote with  . The subset of
. The subset of  where the normalization constraints (Eq. 6) are satisfied we will denote with
where the normalization constraints (Eq. 6) are satisfied we will denote with  . As the update rule for the biases
. As the update rule for the biases  in Table 2 is defined in continuous time, we need to transform it into a form consistent with the previously stated simplification that the updates are performed for one data example drawn from
in Table 2 is defined in continuous time, we need to transform it into a form consistent with the previously stated simplification that the updates are performed for one data example drawn from  , or in other words, that the population of neurons α
fires one spike during the presentation of a data example
, or in other words, that the population of neurons α
fires one spike during the presentation of a data example  . We can do that easily by assuming that the examples are presented for a period of τ (corresponding to one spike sample), which yields the following update for the model parameters encoded in the biases:
. We can do that easily by assuming that the examples are presented for a period of τ (corresponding to one spike sample), which yields the following update for the model parameters encoded in the biases: (31)
(31)
Synaptic and intrinsic plasticity rules in the neural network of the basic learning module
Although in Table 2 the learning rates are different for the weights and the biases, here for simplicity we assume that the learning rate is the same for all parameters. We additionally assume that the sequence of learning rates  satisfies:
satisfies: (33)
(33)
The initial values of the parameters  are randomly drawn from
are randomly drawn from  ).
).
As pointed out previously (see section “Theoretical properties of the basic learning module (stochastic association module) and its plasticity”), in the joint distribution  of the examples zero values of z and xi
do not occur, ie,
of the examples zero values of z and xi
do not occur, ie,  for all i = 1, . . . , I, and additionally
for all i = 1, . . . , I, and additionally  . In the implicitly represented generative model
. In the implicitly represented generative model  the probabilities where at least one of the RVs z and xi
(i = 1, . . . , I) has zero value are represented by the fixed parameters (see Eq. 11 and accompanying text) and are not learned. The fixed parameters assume values (see Eq. 12) so that the corresponding probabilities over zero values are very small, ie, close to zero. Ideally, for the theoretical analysis we set these parameters so that:
the probabilities where at least one of the RVs z and xi
(i = 1, . . . , I) has zero value are represented by the fixed parameters (see Eq. 11 and accompanying text) and are not learned. The fixed parameters assume values (see Eq. 12) so that the corresponding probabilities over zero values are very small, ie, close to zero. Ideally, for the theoretical analysis we set these parameters so that: (34) in order to match the values p*(xi = 0) = 0 and p*(z = 0) = 0. In simulations, the probabilities over zero values represent a very small, insignificant portion of the mass of the learned generative model. This is also true when learning with a network of interconnected learning modules (see section “Theoretical properties of networks of recursively interconnected basic learning modules”).
(34) in order to match the values p*(xi = 0) = 0 and p*(z = 0) = 0. In simulations, the probabilities over zero values represent a very small, insignificant portion of the mass of the learned generative model. This is also true when learning with a network of interconnected learning modules (see section “Theoretical properties of networks of recursively interconnected basic learning modules”).
The assumption (Eq. 34) can be easily achieved by letting in (Eq. 12) the constant V to converge to V → +∞. Indeed, from V → +∞ it follows that  and
and  . The weight offset w– remains constant at any time during the limit process (Eqs. 12, 13). The offset value for the biases does not remain constant, however, it converges to
. The weight offset w– remains constant at any time during the limit process (Eqs. 12, 13). The offset value for the biases does not remain constant, however, it converges to  . To emulate this idealized condition in simulations it is sufficient to set b– to a very large negative value. This ensures that the biases of the active α
neurons converge to large positive values, which then entails that there is always a non-empty subset of α
neurons that have high firing rates upon presentation of an example (see section “Deriving the probability distribution of the firing of the neurons α
”). High firing rates of the α
neurons imply
. To emulate this idealized condition in simulations it is sufficient to set b– to a very large negative value. This ensures that the biases of the active α
neurons converge to large positive values, which then entails that there is always a non-empty subset of α
neurons that have high firing rates upon presentation of an example (see section “Deriving the probability distribution of the firing of the neurons α
”). High firing rates of the α
neurons imply  and consequently
and consequently  in Equation 34. In the section “Theoretical properties of networks of recursively interconnected basic learning modules,” we also demonstrate that after the convergence of the weights and biases during learning to a local optimum, large negative value of b– implies
in Equation 34. In the section “Theoretical properties of networks of recursively interconnected basic learning modules,” we also demonstrate that after the convergence of the weights and biases during learning to a local optimum, large negative value of b– implies  , which is consistent with Equation 34.
, which is consistent with Equation 34.
Finding a local minimum of
through Expectation Maximization

We describe here the EM algorithm applied to the concrete case of finding a local minimum of the objective function  in Equation 26, without any reference to the learning module and how it is implemented there. After we give the convergence proof that the plasticity rules drive the synaptic weights and biases to a local minimum of
in Equation 26, without any reference to the learning module and how it is implemented there. After we give the convergence proof that the plasticity rules drive the synaptic weights and biases to a local minimum of  , we return to the question what mechanisms in the dynamics of the learning module implement different steps of the EM algorithm.
, we return to the question what mechanisms in the dynamics of the learning module implement different steps of the EM algorithm.
The objective function  can be written as follows:
can be written as follows: (35)where
(35)where (36)
(36)
is the log-likelihood function and (37)is the entropy of the RVs x and z with respect to the target joint distribution
(37)is the entropy of the RVs x and z with respect to the target joint distribution  . As
. As  does not depend on the parameters θ
, the constrained local minima of
does not depend on the parameters θ
, the constrained local minima of  match the constrained local maxima of
match the constrained local maxima of  .
.
In the following we will explain the steps of the EM algorithm that finds a local maximum of  . EM optimizes
. EM optimizes  indirectly through another function called the complete data log-likelihood
indirectly through another function called the complete data log-likelihood (38)where
(38)where  is the complete data probability distribution in Equation 29. It is an algorithm that updates the parameters θ
in iterations. We will denote the values of the parameters in current iteration as
is the complete data probability distribution in Equation 29. It is an algorithm that updates the parameters θ
in iterations. We will denote the values of the parameters in current iteration as  . Let
. Let  be the complete data log-likelihood
be the complete data log-likelihood  , where in the probability distribution in the expectation we have the parameter values
, where in the probability distribution in the expectation we have the parameter values  from the current iteration, ie,
from the current iteration, ie, (39)
(39)
The iteration in the EM algorithm consists of two steps:
Expectation step: calculate  as the expectation in Equation 39.
as the expectation in Equation 39.
Maximization step: find parameter values  that satisfy:
that satisfy:
 (40)and then set
(40)and then set  .
.
This is a formulation of EM called the generalized EM algorithm (Dempster et al., 1977). The essence of the algorithm lies in the fact that Equation 40 implies also that: (41)
(41)
which means that in each iteration we increase the value of the log-likelihood. In fact, it also holds that: (42)
(42)
We will refer to this equation when we show that the learning module implements an online stochastic approximation of the generalized EM algorithm outlined here (see text after the convergence proof).
Definition of an auxiliary function
used in the convergence proof

We define here an additional function  , which will be used in the convergence proof. A useful property of
, which will be used in the convergence proof. A useful property of  is that within the parameter domain where the normalization constraints (Eq. 6) are satisfied, it is equal to the log-likelihood function
is that within the parameter domain where the normalization constraints (Eq. 6) are satisfied, it is equal to the log-likelihood function  . Hence, in order to demonstrate in the proof that the plasticity rules minimize
. Hence, in order to demonstrate in the proof that the plasticity rules minimize  , it will be sufficient to show that the rules drive the weights and biases to satisfy the normalization constraints, and when the normalization constraints are satisfied, they maximize
, it will be sufficient to show that the rules drive the weights and biases to satisfy the normalization constraints, and when the normalization constraints are satisfied, they maximize  .
.
The  function is defined as follows:
function is defined as follows: (43)
where
(43)
where  is the marginal of the probability distribution:
is the marginal of the probability distribution:
 (44)
(44)
The numerator of this distribution is the same as in the definition of the generative model  in Equation 5. The difference in the definition between p and q is the denominator. In the denominator in Equation 44,
in Equation 5. The difference in the definition between p and q is the denominator. In the denominator in Equation 44,  is defined as:
is defined as: (45)whereas
(45)whereas (46)
(46)
It can be easily seen that if the normalization constraints (Eq. 6) are satisfied, ie, if  , then
, then (47)from which it follows that:
(47)from which it follows that: (48)
(48)
The derivatives of  with respect to the parameters
with respect to the parameters  are:
are: (49)where
(49)where  is
is (50)
(50)
If we now substitute  in the term inside the expectation in Equation 49 with Equation 44 and simplify, we obtain:
in the term inside the expectation in Equation 49 with Equation 44 and simplify, we obtain: (51)
(51)
Similarly, for the derivative of  with respect to
with respect to  we have the following:
we have the following: (52)and if we substitute Equation 44, we arrive at:
(52)and if we substitute Equation 44, we arrive at: (53)
(53)
Deriving the local minima of
under the constraints

As we stated previously, the constrained local minima of  match the constrained local maxima of the log-likelihood
match the constrained local maxima of the log-likelihood  . Additionally, the constrained local maxima
. Additionally, the constrained local maxima  also match the constrained local maxima of
also match the constrained local maxima of  , because
, because  for all
for all  . Here we derive the local maxima of
. Here we derive the local maxima of  under the normalization constraints in Equation 6in analytical form. The result is used in the main proof in the subsection “The convergence theorem and the proof” where we will show that the sequence
under the normalization constraints in Equation 6in analytical form. The result is used in the main proof in the subsection “The convergence theorem and the proof” where we will show that the sequence  during learning converges exactly to these local maxima.
during learning converges exactly to these local maxima.
The local maxima of  can be found by calculating the derivatives of the Lagrangian function of
can be found by calculating the derivatives of the Lagrangian function of  :
: (54)
(54)
The set of constrained local maxima is a subset of the solutions of the following equations obtained by setting the derivatives of the Lagrangian to 0:
 (55)
(55)
By summing the left and right sides of all equations in which λ0 occurs, and by using the equalities  and
and  , we obtain a solution for the Lagrange multiplier equal to
, we obtain a solution for the Lagrange multiplier equal to
 (56)
(56)
Similarly, if we sum the left and right sides of all equations where  occurs, and if we use the equalities
occurs, and if we use the equalities  and
and  , we arrive at:
, we arrive at: (57)
(57)
Interestingly, as all Lagrangian multipliers are 0, the critical points of the Lagrangian are also critical points of  , which means that the constrained local maxima of
, which means that the constrained local maxima of  are also its unconstrained local maxima.
are also its unconstrained local maxima.
Based on these solutions for the Lagrange multipliers, we get from Equation 55 the following implicit solutions for the parameters  and
and  :
: (58)where
(58)where  and
and  are marginal and conditional distributions derived from
are marginal and conditional distributions derived from  in Equation 50. Note that these are implicit solutions, since
in Equation 50. Note that these are implicit solutions, since  and
and  depend on the parameters θ
. It can be easily verified that the solutions of Equation 58 fulfill the normalization constraints. Indeed:
depend on the parameters θ
. It can be easily verified that the solutions of Equation 58 fulfill the normalization constraints. Indeed: (59)
(59)
and also: (60)
(60)
Therefore, we can substitute in the implicit solutions the probability distribution  with
with  from (29), which yields:
from (29), which yields: (61)
(61)
We will denote the set of all finite points θ
that satisfy Equation 61 as G. It is assumed that the bounds of the parameters wmin
and bmin
are chosen so that  . The critical points of the Lagrangian in G are either local maxima, local minima, or saddle points of the objective function
. The critical points of the Lagrangian in G are either local maxima, local minima, or saddle points of the objective function  in Equation 26under the normalization constraints in Equation 6.
in Equation 26under the normalization constraints in Equation 6.
The convergence theorem and the proof
After introducing the necessary definitions and notations in the previous subsections, we use them here to restate the Theorem 1 from the subsection “The plasticity rules minimize the KL divergence through Expectation Maximization” in more technical terms.
Theorem 1*. The infinite sequence  in Equation 30 converges with probability 1 to the set of local minima of
in Equation 30 converges with probability 1 to the set of local minima of  in Equation 26 subject to the normalization constraints (Eq. 6).
in Equation 26 subject to the normalization constraints (Eq. 6).
Proof: We define a “mean limit” ordinary differential equation (ODE) that corresponds to the sequence  as
as  , where
, where  . Here
. Here  is defined with the plasticity rules in Table 2. As for all n the parameters
is defined with the plasticity rules in Table 2. As for all n the parameters  remain in the bounded set
remain in the bounded set  , it follows that
, it follows that  and
and  .
.
In order to prove convergence, we use the stochastic convergence Theorem 3.1 in Chapter 5 from Kushner and Yin, (2003) which states that, under the above assumptions, the sequence  from Equation 30 converges with probability 1 to the stable points of the limit set of the mean limit ODE for all initial conditions
from Equation 30 converges with probability 1 to the stable points of the limit set of the mean limit ODE for all initial conditions  . The limit set of the mean limit ODE with respect to a set of the initial conditions
. The limit set of the mean limit ODE with respect to a set of the initial conditions  , which we denote as F(A), is defined as:
, which we denote as F(A), is defined as: (62)
(62)
Convergence to the limit set F(A) with probability 1 means that for all stochastic realizations of the sequence  it holds that:
it holds that: (63)
(63)
The main part of the proof will be to show that  , ie, that the limit set of the ODE with the set of initial values
, ie, that the limit set of the ODE with the set of initial values  is equal to the critical points of the Lagrangian
is equal to the critical points of the Lagrangian  , which are also critical points of
, which are also critical points of  . We will show that in two steps. First, we will show that all trajectories of the ODE asymptotically converge to the set
. We will show that in two steps. First, we will show that all trajectories of the ODE asymptotically converge to the set  where the normalization constraints (Eq. 6) are satisfied. Then in the second step, we will show that all trajectories with initial conditions
where the normalization constraints (Eq. 6) are satisfied. Then in the second step, we will show that all trajectories with initial conditions  converge to G.
converge to G.
Let  and
and  be the functions that express how much the sums in the normalization constraints (Eq. 6) deviate from 1, ie:
be the functions that express how much the sums in the normalization constraints (Eq. 6) deviate from 1, ie: (64)
(64)
For all points θ
in the set  , where the constraints are satisfied, we have
, where the constraints are satisfied, we have  and
and  (for all l≠0 and all i and j). We now analyze how the values of
(for all l≠0 and all i and j). We now analyze how the values of  and
and  change when θ
progresses along a solution trajectory of the mean limit ODE. For that purpose we calculate the dot products between
change when θ
progresses along a solution trajectory of the mean limit ODE. For that purpose we calculate the dot products between  and the gradients of
and the gradients of  and
and  . The non-zero components of the gradient of
. The non-zero components of the gradient of  are:
are: (65)
(65)
Similarly the gradient of  has the following non-zero components:
has the following non-zero components: (66)
(66)
Thus, for the dot products we have: (67)
(67)
and
 (68)where
(68)where  is a marginal of
is a marginal of  . From these equations we can conclude that
. From these equations we can conclude that  and
and  for all
for all  and all i and j. Thus, because
and all i and j. Thus, because  is continuous and differentiable in
is continuous and differentiable in  , it follows that the limit set of the ODE for initial conditions
, it follows that the limit set of the ODE for initial conditions  is inside
is inside  , ie,
, ie,  . Additionally, the differentiability and continuity of
. Additionally, the differentiability and continuity of  imply that
imply that  and
and  if
if  , for all
, for all  . By using these properties, we can derive that:
. By using these properties, we can derive that: (69)
(69)
We continue now with the second step of the proof where we show that trajectories starting within  converge to the critical points of the Lagrangian
converge to the critical points of the Lagrangian  . First, from Equations 67 and 68, it follows that
. First, from Equations 67 and 68, it follows that  and
and  for all
for all  . This means that trajectories
. This means that trajectories  with
with  remain in
remain in  , ie,
, ie,  for all
for all  . Furthermore, it is easy to show that the set of critical points G of the Lagrangian
. Furthermore, it is easy to show that the set of critical points G of the Lagrangian  written in implicit form in Equation 61is the same as the set of the stationary points of the mean limit ODE obtained as a solution of the equation
written in implicit form in Equation 61is the same as the set of the stationary points of the mean limit ODE obtained as a solution of the equation  . What remains to be shown is that the trajectory always converges with probability 1 to one of the stationary points in G, ie, that for example it does not enter a limit cycle. We do that by analyzing how the function
. What remains to be shown is that the trajectory always converges with probability 1 to one of the stationary points in G, ie, that for example it does not enter a limit cycle. We do that by analyzing how the function  changes along the trajectory of the ODE by calculating the dot product between
changes along the trajectory of the ODE by calculating the dot product between  and the gradient
and the gradient  given in Equations 51 and 53. As for
given in Equations 51 and 53. As for  it holds that
it holds that  and
and  , the dot product is:
, the dot product is: (70)and becomes equal to zero for the set of stationary points
(70)and becomes equal to zero for the set of stationary points  which is the same as the set G. Hence, the ODE trajectories do not have any limit cycles and always converge to the critical points of the Lagrangian G, ie,
which is the same as the set G. Hence, the ODE trajectories do not have any limit cycles and always converge to the critical points of the Lagrangian G, ie,  . Together with the conclusion (Eq. 69) of the first step, we finally obtain that the limit set of the ODE is:
. Together with the conclusion (Eq. 69) of the first step, we finally obtain that the limit set of the ODE is: (71)
(71)
According to the stochastic convergence Theorem 3.1 in Chapter 5 from Kushner and Yin (2003), the infinite sequence  converges to the stable points of the limit set G. Stochastic fluctuations would drive the sequence to escape from the unstable points in the limit set. We have shown in Equation 70 that
converges to the stable points of the limit set G. Stochastic fluctuations would drive the sequence to escape from the unstable points in the limit set. We have shown in Equation 70 that  increases along an ODE trajectory that starts within
increases along an ODE trajectory that starts within  . This implies that also
. This implies that also  increases as
increases as  for
for  . Thus, it follows that the stable points of the ODE in G are the local constrained maxima of
. Thus, it follows that the stable points of the ODE in G are the local constrained maxima of  , subject to the normalization constraints, which concludes the proof.
, subject to the normalization constraints, which concludes the proof.
By using results from the proof, we can now more precisely relate the update of the synaptic weights and biases by the plasticity rules to the maximization step of the EM algorithm, as discussed in subsection “The plasticity rules minimize the KL divergence through Expectation Maximization.” In the WTA circuit the plasticity rules update the weights and biases online, after each spike of a neuron in α
. If we instead consider an offline update where the updates are averaged over many spikes of the α
neurons (theoretically infinitely many), and then afterward they are applied to the weights and biases, then this offline update of the parameter vector in the limit of infinite number of spikes would be equal to: (72)
(72)
The vector  is the gradient of the ODE trajectory, which means that for a sufficiently small learning rate the offline mean update will always increase the expected log-likelihood
is the gradient of the ODE trajectory, which means that for a sufficiently small learning rate the offline mean update will always increase the expected log-likelihood  provided that
provided that  . This follows from the fact that
. This follows from the fact that  increases along the ODE trajectory as we have shown in the proof (Equation 70 and the text afterward). Furthermore, the off-line mean update increases
increases along the ODE trajectory as we have shown in the proof (Equation 70 and the text afterward). Furthermore, the off-line mean update increases  by calculating an expectation over the complete data samples from the distribution (Eq. 29) which represents the expectation step of the EM algorithm. In the subsection “The plasticity rules minimize the KL divergence through Expectation Maximization,” we already showed that the spikes of the neurons α
together with the presented examples represent the complete data samples drawn from Equation 29. This clarifies that the offline mean update of the plasticity rules indeed implements the maximization step of the generalized EM algorithm as defined in Equations 42 and 40. From this, it follows that the online plasticity rules implement an online stochastic approximation version of the maximization step of EM.
by calculating an expectation over the complete data samples from the distribution (Eq. 29) which represents the expectation step of the EM algorithm. In the subsection “The plasticity rules minimize the KL divergence through Expectation Maximization,” we already showed that the spikes of the neurons α
together with the presented examples represent the complete data samples drawn from Equation 29. This clarifies that the offline mean update of the plasticity rules indeed implements the maximization step of the generalized EM algorithm as defined in Equations 42 and 40. From this, it follows that the online plasticity rules implement an online stochastic approximation version of the maximization step of EM.
The proof of Theorem 1 (reformulated in Theorem 1* in this subsection) completes the theory behind the learning mechanisms and learning capabilities of the learning module described in Results, section “A network module for learning stochastic associations.” In particular, it rigorously shows that the learning module learns, via the EM algorithm, an internal model of the probabilistic relations between a set of variables x and another variable z in the presented examples.
Theoretical properties of networks of recursively interconnected basic learning modules
This section contains additional details on the learning approach with networks of recursively connected learning modules, that we described in Results, section “Recursive combinations of the basic learning module enable efficient learning of complex distributions from examples.” After presenting the learning procedure for such networks, we will formulate in this section Theorem 2 which contains the theoretical basis of learning with networks of learning modules. Theorem 2 is derived from Theorem 1 (see section “The plasticity rules minimize the KL divergence through Expectation Maximization”), and shows that the plasticity mechanisms in a network of modules minimize another objective function that pertains to the represented probabilistic model in the whole network. This minimization then leads to learning an internal model of the stochastic associations between all variables yk of the presented examples.
The population of neurons that encodes the values of the RV yk
(t) over time t we denote with  (these are the output neurons of the learning module
(these are the output neurons of the learning module  ). For each non-zero value l of yk
, there is a neuron νkl
whose firing signals this value. In particular, a spike of the neuron νkl
at time t sets the value of yk
to yk
= l for a time period of duration τ, after which the value changes to yk
= 0. To ensure a valid value of yk
, no other neuron in
). For each non-zero value l of yk
, there is a neuron νkl
whose firing signals this value. In particular, a spike of the neuron νkl
at time t sets the value of yk
to yk
= l for a time period of duration τ, after which the value changes to yk
= 0. To ensure a valid value of yk
, no other neuron in  should fire in the time interval [t, t + τ). This is ensured by the lateral inhibition between the
should fire in the time interval [t, t + τ). This is ensured by the lateral inhibition between the  neurons, which drive the
neurons, which drive the  neurons to fire.
neurons to fire.
The network learns from presented examples 
 drawn from the target probability distribution
drawn from the target probability distribution  . In the examples the RV yk
assumes an integer value drawn from the set
. In the examples the RV yk
assumes an integer value drawn from the set  . An example is presented to the network in form of injected currents in the neurons. These injected currents are assumed to originate from external neurons. The neurons in
. An example is presented to the network in form of injected currents in the neurons. These injected currents are assumed to originate from external neurons. The neurons in  are driven by the injected currents such that their firing reflects correctly the values of the RVs yk
in the current example
are driven by the injected currents such that their firing reflects correctly the values of the RVs yk
in the current example  . More precisely, for
. More precisely, for  the neuron νkl
receives strong positive current and fires with a high firing rate, whereas the other neurons in the population
the neuron νkl
receives strong positive current and fires with a high firing rate, whereas the other neurons in the population  receive a strong negative current, which prevents them from firing. The neurons α
also have currents injected during learning, that give information about the current example, exactly in the same way as explained for a single learning module (see section “Theoretical properties of the basic learning module (stochastic association module) and its plasticity”), where the presented example
receive a strong negative current, which prevents them from firing. The neurons α
also have currents injected during learning, that give information about the current example, exactly in the same way as explained for a single learning module (see section “Theoretical properties of the basic learning module (stochastic association module) and its plasticity”), where the presented example  is here for the learning module
is here for the learning module  equal to
equal to  (Fig. 5).
(Fig. 5).
The mathematical symbols that are used in the definition of the neural network are listed in Table 3.
Mathematical symbols used in the definition of the network of interconnected learning modules
As we stated in the section “Theoretical properties of the basic learning module (stochastic association module) and its plasticity,” only the non-zero values of z represent meaningful states of the external environment and are learned. The probability of the zero value  is not learned, and converges always to a very small value during learning. This can be easily seen if we express
is not learned, and converges always to a very small value during learning. This can be easily seen if we express  through the firing probability densities
through the firing probability densities  of the α
neurons given input x:
of the α
neurons given input x: (73)
(73)
From the inequality  it follows that:
it follows that: (74)
(74)
If we substitute Equation 14 for the biases and use b– = −V, which follows from Equations 12 and 15, we obtain: (75)
(75)
According to the proof of Theorem 1* (Eq. 67), during learning the plasticity rules drive the synaptic weights and biases of the α
neurons toward satisfying the normalization constraints in Equation 6, which simplifies Equation 75 to  . As V is a very large positive constant (Eq. 12 and accompanying text), we finally arrive at:
. As V is a very large positive constant (Eq. 12 and accompanying text), we finally arrive at: (76)
(76)
Hence, we have shown that after learning, the sum of the firing probabilities of the output ζ
neurons is always very high (when inhibition is not active), regardless of the current input x. Similarly, in case of a network of learning modules, after learning, the output  neurons in each module in the network are in strong competition and
neurons in each module in the network are in strong competition and  is very small. From this it follows that in the stochastic dynamics of the spiking neural network states where there is a RV yk
with value yk
= 0 occur for very short time intervals, ie, they have very small probability in the internal model distribution
is very small. From this it follows that in the stochastic dynamics of the spiking neural network states where there is a RV yk
with value yk
= 0 occur for very short time intervals, ie, they have very small probability in the internal model distribution  . Note that in the examples drawn from the target probability distribution p* such states are not present as the RVs yk
in the examples have values from 1 to M(yk
). The zero values occur only in the neural network dynamics and they do not refer to meaningful values of variables in the external environment.
. Note that in the examples drawn from the target probability distribution p* such states are not present as the RVs yk
in the examples have values from 1 to M(yk
). The zero values occur only in the neural network dynamics and they do not refer to meaningful values of variables in the external environment.
In order to show that if each learning module  learns an approximation of
learns an approximation of  in its internal model
in its internal model  then the stationary distribution of the whole network is close to
then the stationary distribution of the whole network is close to  , we use as a theoretical basis the neural computability condition (NCC) from Pecevski et al., (2011) and Buesing et al. (2011). The NCC has been identified there as a sufficient condition for representing a particular distribution p* as stationary distribution of a network of spiking neurons. If the NCC is satisfied, then the stochastic dynamics of the resulting network produces (after some burn-in phase, whose length depends on the choice of its initial state) spontaneously network states (samples) that are drawn according to p*. The network state is represented here as the vector of the RV values y(t) at time t, where the value of each RV yk
(t) at time t is encoded in the spikes of the population of neurons
, we use as a theoretical basis the neural computability condition (NCC) from Pecevski et al., (2011) and Buesing et al. (2011). The NCC has been identified there as a sufficient condition for representing a particular distribution p* as stationary distribution of a network of spiking neurons. If the NCC is satisfied, then the stochastic dynamics of the resulting network produces (after some burn-in phase, whose length depends on the choice of its initial state) spontaneously network states (samples) that are drawn according to p*. The network state is represented here as the vector of the RV values y(t) at time t, where the value of each RV yk
(t) at time t is encoded in the spikes of the population of neurons  as described above. In order to have p* as a stationary distribution of network states, the NCC requires that the firing probability density of νkl
should be equal to
as described above. In order to have p* as a stationary distribution of network states, the NCC requires that the firing probability density of νkl
should be equal to (77)if the current value of yk
is yk
(t) = 0, and otherwise the neuron should be silent. If
(77)if the current value of yk
is yk
(t) = 0, and otherwise the neuron should be silent. If  , as we assumed is the case in the presented examples, the NCC transforms as follows: the firing probability density of νkl
at time t should be proportional to
, as we assumed is the case in the presented examples, the NCC transforms as follows: the firing probability density of νkl
at time t should be proportional to 
 (78)if yk
(t) = 0, and should be 0 otherwise. Additionally, the firing probability densities ρkl
for all principal neurons in the population
(78)if yk
(t) = 0, and should be 0 otherwise. Additionally, the firing probability densities ρkl
for all principal neurons in the population  should be large enough so that if the spike of the last neuron was at time t, a new neuron fires almost immediately after t + τ, ie, the in-between time period where yk
(t) = 0 should be very short (ideally its duration should be equal to 0).
should be large enough so that if the spike of the last neuron was at time t, a new neuron fires almost immediately after t + τ, ie, the in-between time period where yk
(t) = 0 should be very short (ideally its duration should be equal to 0).
The firing probability density of the neuron νkl
in the network is, according to Equation 19, equal to: (79)as it is one of the output neurons of the learning module
(79)as it is one of the output neurons of the learning module  . In addition, as we have shown above, the probability
. In addition, as we have shown above, the probability  after learning has a very small value, which makes the firing probabilities
after learning has a very small value, which makes the firing probabilities  very high. We see that Equation 79 has the same form as the firing probability (Eqs. 77 and 78) in the NCC, except that here we have the model conditional
very high. We see that Equation 79 has the same form as the firing probability (Eqs. 77 and 78) in the NCC, except that here we have the model conditional  instead of the target conditional
instead of the target conditional  in the NCC. Thus, as the plasticity rules during learning change the weights and biases toward reducing the difference between
in the NCC. Thus, as the plasticity rules during learning change the weights and biases toward reducing the difference between  and
and  , which is an upper bound of the difference between the corresponding conditionals (Eq. 28), this then should bring the firing probability
, which is an upper bound of the difference between the corresponding conditionals (Eq. 28), this then should bring the firing probability  from Equation 79 closer to the desired firing probability in the NCC (Eq. 78).
from Equation 79 closer to the desired firing probability in the NCC (Eq. 78).
The objective function  for learning in the whole network can be formulated as the sum of the objective functions
for learning in the whole network can be formulated as the sum of the objective functions  of all learning modules
of all learning modules  :
: (80)
(80)
Using  we can state the following theorem for learning in the whole network:
we can state the following theorem for learning in the whole network:
Theorem 2. The synaptic and intrinsic plasticity rules in Equations 1, 2, and 3 change the parameters θ
in a way so that they always converge to a local minimum of  subject to the normalization constraints (Eq. 6).
subject to the normalization constraints (Eq. 6).
Theorem 2 directly follows from Theorem 1 and from the fact that each of the KL divergences in the sum are parametrized by a separate set of parameters  . If
. If  then according to the NCC we have that
then according to the NCC we have that  . If the parameters converge to a good local minimum of
. If the parameters converge to a good local minimum of  so that the learning modules in the network learn a good approximation of the firing probability densities of the NCC, then the stationary probability distribution
so that the learning modules in the network learn a good approximation of the firing probability densities of the NCC, then the stationary probability distribution  of the network would approximate well the target distribution
of the network would approximate well the target distribution  .
.
During its spontaneous activity the neural network enters states where there is at least one RV yk
with zero value. These states are not part of the target distribution p*. Nevertheless, as that the output neurons after learning fire with very high firing rates when not inhibited (Eqs. 73–76), the states with zero values occur only for very short time intervals and should not affect the correct Markov chain Monte Carlo sampling process of the stochastic network. Therefore, if the output neurons of the modules learn to fire approximately according to the NCC (78) and fire with very high firing rates, the distribution of the network states during spontaneous activity  should be a good approximation to
should be a good approximation to  , as we show in our computer simulations.
, as we show in our computer simulations.
If it satisfies the NCC, the neural network cannot only generate samples from p*, but it can also perform via sampling probabilistic inference based on p* (described in Results, section “Flexible retrieval of learnt statistical information through probabilistic inference”). In a typical probabilistic inference task evidence is provided for a subset of the RVs ye
, ie, their values are known, and one wants to calculate the posterior distribution  for some of the unknown RVs ys
given the evidence. In the neural network, the evidence is presented by clamping the neurons with injected input currents. For example, if the value of the RV yk
is yk
= l, then positive current from exogenous neurons is injected in the neuron νkl
such that it fires with high firing rate, whereas all other neurons in the population
for some of the unknown RVs ys
given the evidence. In the neural network, the evidence is presented by clamping the neurons with injected input currents. For example, if the value of the RV yk
is yk
= l, then positive current from exogenous neurons is injected in the neuron νkl
such that it fires with high firing rate, whereas all other neurons in the population  are kept silent through a negative injected current. A basic property of the network is that when evidence is injected in it, it changes its dynamics such that the neurons for the unknown RVs ys
generate samples exactly from the posterior
are kept silent through a negative injected current. A basic property of the network is that when evidence is injected in it, it changes its dynamics such that the neurons for the unknown RVs ys
generate samples exactly from the posterior  . The posterior probabilities can then be estimated simply by counting the generated samples.
. The posterior probabilities can then be estimated simply by counting the generated samples.
Details to computer simulations
Details to the computer simulation in Example 2
All computer simulations were carried out with NEVESIM, an event-based neural network simulator developed in C++ with a Python interface (Pecevski et al., 2014). The simulator NEVESIM builds on techniques developed in the simulator PCSIM (Pecevski et al., 2009). In all simulations we used the stochastic point neuron model from Buesing et al. (2011) and Pecevski et al. (2011). The parameter τ that defines the encoding of values of the RVs by the spikes was equal to τ = 15 ms. The neurons had absolute refractory period of duration τ. The lateral inhibition in the WTA circuits was implemented with a population of five inhibitory neurons, where all neurons in the population α
connect to these inhibitory neurons with a synaptic weight we2i = 80. The bias of the inhibitory neurons in the lateral inhibition was set to binh
= −10, and the bias of all neurons corresponding to the RVs y was also set to bpp
= −10. The weights of the strong input synaptic connections to each neuron νkl
, that originated from its corresponding group of neurons in  that drive it to fire, were set to wpp
= 20. During learning, the evolution of all synaptic weights was confined within a range [wmin
, wmax
], where wmin
= 0, wmax = 4 for the synapses of the α
neurons in the learning modules
that drive it to fire, were set to wpp
= 20. During learning, the evolution of all synaptic weights was confined within a range [wmin
, wmax
], where wmin
= 0, wmax = 4 for the synapses of the α
neurons in the learning modules  and
and  , and wmax
= 2 for the synapses of the α
neurons of module
, and wmax
= 2 for the synapses of the α
neurons of module  . Synaptic weight changes induced by the plasticity rule that would go below wmin
, or above wmax
, were clipped to wmin
, or wmax
, respectively.
. Synaptic weight changes induced by the plasticity rule that would go below wmin
, or above wmax
, were clipped to wmin
, or wmax
, respectively.
At the beginning of each probabilistic inference simulation, the state of the network (defined by the RV values y(t)) was initialized according to a random state drawn from a uniform distribution over all possible initial network states. This was done by injecting very short current pulses in the neurons in the populations  . During the probabilistic inference simulations, evidence for the known values of the RVs was given to the network by injecting external currents in the
. During the probabilistic inference simulations, evidence for the known values of the RVs was given to the network by injecting external currents in the  neurons of the known RVs. The currents were injected in exactly the same way and with exactly the same amplitudes as during the presentation of the examples in the learning process (see below).
neurons of the known RVs. The currents were injected in exactly the same way and with exactly the same amplitudes as during the presentation of the examples in the learning process (see below).
During learning, the presented examples were generated from the Bayesian network in Figure 6B, with the values for the conditional probabilities given in Table 4. The prior probabilities  and
and  were both equal to 0.5.
were both equal to 0.5.
Values for the conditional probabilities in the Bayesian network in Figure 6B used to generate examples for learning in Example 2
During the presentation of the examples, the neuron νkl
had injected a strong positive current Ipp
+ = 30 if yk
= l in the example, or a strong negative current Ipp– = −30 if in the example yk
≠ l. Additionally, if in the current example yk = l, then a strong negative external current with amplitude  was injected in each of the neurons in the population
was injected in each of the neurons in the population  that are not in the subpopulation
that are not in the subpopulation  , whereas the neurons in
, whereas the neurons in  did not receive any external current.
did not receive any external current.
Each subpopulation  in every learning module in the network consisted of two neurons. All excitatory neurons in the network had an alpha shaped EPSP defined by the kernel:
in every learning module in the network consisted of two neurons. All excitatory neurons in the network had an alpha shaped EPSP defined by the kernel:
 (81)
(81)
Here  is a scaling factor, t1 and t2 and are the points in time where the basic alpha kernel of the form
is a scaling factor, t1 and t2 and are the points in time where the basic alpha kernel of the form  is equal to
is equal to  , and τα
= 8.5 ms is the time constant of the alpha kernel. The same shape of the EPSPs was also used by Pecevski et al. (2011). After an incoming spike at the synapse at time
, and τα
= 8.5 ms is the time constant of the alpha kernel. The same shape of the EPSPs was also used by Pecevski et al. (2011). After an incoming spike at the synapse at time  , the time course of the EPSP is equal to
, the time course of the EPSP is equal to  (w is the synaptic efficacy) until the next spike at
(w is the synaptic efficacy) until the next spike at  after which it is set to
after which it is set to  . The PSPs at the synapses connecting from, and to, the inhibitory neurons of the lateral inhibition had a rectangular shape with duration of τ = 15 ms. The rectangular IPSPs of the inhibitory neurons approximate the effect that fast-spiking bursting inhibitory neurons with short duration IPSPs would have on the membrane potential of the neurons α
. The synaptic weights of the connections from the inhibitory neurons in the lateral inhibition to the neurons α
were all equal to wi
2e
= −7.
. The PSPs at the synapses connecting from, and to, the inhibitory neurons of the lateral inhibition had a rectangular shape with duration of τ = 15 ms. The rectangular IPSPs of the inhibitory neurons approximate the effect that fast-spiking bursting inhibitory neurons with short duration IPSPs would have on the membrane potential of the neurons α
. The synaptic weights of the connections from the inhibitory neurons in the lateral inhibition to the neurons α
were all equal to wi
2e
= −7.
Before the start of learning, the synaptic weights of all neurons in α
were initialized randomly from a Gaussian distribution with mean  and SD σw
0 = 0.1. If the randomly drawn value was not in the interval [wmin
, wmax
], then it was redrawn again until the new value was in the interval (the same type of redrawing was done for the initial values of the biases). The initial biases of the α
neurons were randomly drawn from a Gaussian distribution with mean
and SD σw
0 = 0.1. If the randomly drawn value was not in the interval [wmin
, wmax
], then it was redrawn again until the new value was in the interval (the same type of redrawing was done for the initial values of the biases). The initial biases of the α
neurons were randomly drawn from a Gaussian distribution with mean  and SD σb
0 = 0.1. The evolution of the biases of the neurons in α
was restricted to be in the range [bmin
, bmax
] with bmin = –30 and bmax = 5. If the intrinsic plasticity changed the bias above bmax
or below bmin
, the bias was clipped to bmax
or bmin
, respectively. In the learning rules we introduced an additional scaling factor T = 0.58 in the potentiation part. In particular, the potentiation part of the learning rule (Eq. 1) for the weights had the form
and SD σb
0 = 0.1. The evolution of the biases of the neurons in α
was restricted to be in the range [bmin
, bmax
] with bmin = –30 and bmax = 5. If the intrinsic plasticity changed the bias above bmax
or below bmin
, the bias was clipped to bmax
or bmin
, respectively. In the learning rules we introduced an additional scaling factor T = 0.58 in the potentiation part. In particular, the potentiation part of the learning rule (Eq. 1) for the weights had the form  , and the potentiation part of the learning rule (Eq. 2) for the biases had form
, and the potentiation part of the learning rule (Eq. 2) for the biases had form  .
.
The learning process lasted 1200 s of biological time. During the first 600 s of learning, the learning rate for the synaptic weights was decreasing linearly from  at t = 0 to
at t = 0 to  at t = 600 s. In the second 600 s of the learning, after t = 600 s, the synaptic plasticity was not active, ie, the learning rate was set to η = 0. The learning rate for the biases during the first 600 s was constant and equal to
at t = 600 s. In the second 600 s of the learning, after t = 600 s, the synaptic plasticity was not active, ie, the learning rate was set to η = 0. The learning rate for the biases during the first 600 s was constant and equal to  . In the second part of learning, after t = 600, it had another constant value equal to
. In the second part of learning, after t = 600, it had another constant value equal to  .
.
The offset parameter in the synaptic plasticity rule was equal to  , whereas the offset parameter of the intrinsic plasticity in the neuron
, whereas the offset parameter of the intrinsic plasticity in the neuron  was:
was: (82)where
(82)where  is the number of RVs in the Markov blanket of yk
, I
B
(
k
) is the set of indices of the variables yi
that are in the Markov blanket of yk
, T is the scaling factor in the learning rule (see above) and M(yi
) denotes the largest value of the RV yi
. As the neurons
is the number of RVs in the Markov blanket of yk
, I
B
(
k
) is the set of indices of the variables yi
that are in the Markov blanket of yk
, T is the scaling factor in the learning rule (see above) and M(yi
) denotes the largest value of the RV yi
. As the neurons  in different learning modules have different number of input synapses, the bias offset parameter was set for each neuron to counter-balance appropriately the average total input it receives from the input synapses.
in different learning modules have different number of input synapses, the bias offset parameter was set for each neuron to counter-balance appropriately the average total input it receives from the input synapses.
In Figure 7B, the frequency of the network states was calculated from the spontaneous activity of the neural network after learning, simulated for 20 s biological time. The neural network was initialized to be in a random network state at t = 0. In Figure 8C, the KL divergence was calculated at 1 min time intervals, ie, at time points t = 60i seconds (i = 0, . . . ,19). At each time point, the distribution  was estimated by simulating the neural network with the values of the synaptic weights and biases of the neurons at the particular time point. The network was simulated for 1500 s, and the estimated probabilities were calculated from the network states in the time interval
was estimated by simulating the neural network with the values of the synaptic weights and biases of the neurons at the particular time point. The network was simulated for 1500 s, and the estimated probabilities were calculated from the network states in the time interval  of the simulation. In Figure 8 Panels, A, B, and D, the distributions
of the simulation. In Figure 8 Panels, A, B, and D, the distributions  and
and  of the learning modules were calculated analytically by using Equation 5, and then marginalizing α
.
of the learning modules were calculated analytically by using Equation 5, and then marginalizing α
.
Details to the computer simulations in Example 1
The target probability distribution  from which examples were generated is given in Table 5. The scaling factor T in the learning rules (see section “Details to the computer simulation in Example 2”) was set to T = 0.4. The maximum weight value was in this example wmax
= 5. Before learning, the synaptic weights of all neurons in α
were initialized randomly from a Gaussian distribution with mean
from which examples were generated is given in Table 5. The scaling factor T in the learning rules (see section “Details to the computer simulation in Example 2”) was set to T = 0.4. The maximum weight value was in this example wmax
= 5. Before learning, the synaptic weights of all neurons in α
were initialized randomly from a Gaussian distribution with mean  and SD
and SD  . All other parameters in this example that define the learning module, as well as the learning process, were the same as the parameters of the learning modules in the computer simulation in Example 2 (see section “Details to the computer simulation in Example 2”).
. All other parameters in this example that define the learning module, as well as the learning process, were the same as the parameters of the learning modules in the computer simulation in Example 2 (see section “Details to the computer simulation in Example 2”).
The target probability distribution  in Example 1
in Example 1
Discussion
Numerous models for probabilistic inference in networks of neurons have been proposed, and many models for the impact of learning on network computations have been proposed. However, surprisingly, these two lines of research have so far (with a few exceptions that are discussed below) not been brought together. We propose in this article a new model for learning and memory organization in recurrent networks of spiking neurons that makes the information that is gathered from numerous experiences immediately available for complex and unforeseen memory retrievals in the form of probabilistic inference. The network is able to perform such probabilistic inference just through its inherent stochastic dynamics. More precisely, we assume that the network receives samples (=examples) from some unknown multivariate distribution p*, and show that a suitably structured recurrent network of spiking neurons is able to build through STDP and intrinsic plasticity of the excitability of neurons an internal model for p* in such a way, that it can answer a diverse repertoire of probabilistic inference queries about the stored knowledge through sampling. Early models for memory storage and retrieval in recurrent networks of artificial neurons (Steinbuch, 1961; Hopfield, 1982, 1984) had focused on the storage of isolated memory items in attractors of a deterministic network dynamics. The only memory queries that are considered in these models are input completion tasks, or finding the most similar memory item to the input pattern. Answering queries that require the combination of several stored memory items is virtually impossible in such model, especially because the stored memory items were required to be scrambled (orthogonalized) before they were committed to the network. This is inconsistent with experimental data on human memory, which require a substantially more structured memory organization (Stickgold and Walker, 2013).
We have shown in this article, that very simple network motifs (Fig. 2) provide learning modules, which can extract probabilistic relationships between random variables from examples, simply by applying STDP and intrinsic plasticity. One feature of these network motifs is that different groups of neurons on layer 2 project to different neurons on layer 3. Such nonconvergent synaptic connections are difficult to identify with current experimental methods, but have already been found in the mouse cortex (Chen et al., 2013), where largely nonoverlapping populations of pyramidal cells in layer 2/3 of area S1 project to areas S2 and M1. Somewhat similar fine-scale connectivity patterns had previously been found within a cortical column of rat visual cortex (Yoshimura et al., 2005; Kampa et al., 2006). It remains to be tested whether these fine-scale network structures in the brain support the learning of stochastic associations as predicted by our model.
These simple stochastic association modules can be recursively combined (Figs. 4, 5), and are then able to learn also complex stochastic relationships, including higher order moments (eg, explaining away), from examples. We have demonstrated this for a well-known visual inference task from Knill and Kersten (1991), which is known to require explaining away (Figs. 6–9), but where it has been an open question whether brains could in principle acquire this capability through learning. Furthermore, we have shown that this impressive learning capability of recurrent networks of spiking neurons can be understood for simple rules for STDP and intrinsic plasticity of neurons on the basis of a rigorous mathematical theory (Expectation Maximization).
The representations of statistical knowledge in networks of spiking neurons that are shown here to result from learning are structurally very similar to previously proposed ones by Pecevski et al. (2011) that were based on construction instead of learning, with one important difference: whereas the constructed networks required very large numbers of auxiliary neurons for representing random variables with larger Markov blankets, we show here that similar networks but with realistic numbers of hidden (auxiliary) neurons can still provide good approximations. These smaller modules automatically learn to make optimal use of the number of auxiliary neurons that are available to them. They learn automatically to approximate complex stochastic associations between random variables that emerge from examples, with a mixture distribution whose maximal number of components (modes) fits to the available number of auxiliary neurons. We have demonstrated this important feature of our learning approach in Figure 3 (compare panels B,D and C,E) and in our model for explaining away in Figure 6 (where the number of auxiliary neurons in the learning modules (Fig. 6D) is smaller than the number required by the construction of Pecevski et al.(2011)).
One other interesting general feature of our model is that it shows how noise in networks of neurons can be beneficial. In fact, noise provides here a necessary ingredient both for the self-organization of the network through STDP, and for the use of learnt probabilistic relationships for probabilistic inference via MCMC sampling (Habenschuss et al., 2013a). The necessary stochasticity in the neurons can come from different sources like for example the unreliable neurotransmitter release from the vesicles at the presynaptic site, or the stochastic closing and opening of membrane ion channels (Faisal et al., 2008).
Finally, we would like to point out that our network model produces answers to probabilistic inference queries (Fig. 9) in the form of firing rates, which is obviously useful for communicating such answers to downstream networks. Internally however, the network works with a spike-based encoding of network states, where every spike has an impact on the network state (Fig. 7).
Our model and theory has identified concrete plasticity mechanisms and network architectures that would enable networks of neurons in the brain to build probabilistic internal models for their stochastic environment. We have focused here on an idealized model in order to keep it theoretically tractable. Further work will have to explore to what extent similar learning phenomena arise in more complex neural network models that sacrifice theoretical tractability for additional biological details.
Related work
There are several studies that propose neural implementations of probabilistic inference in general graphical models where, as in our approach, the present independencies of the distribution are directly exploited for reducing the complexity of the neural network structure. The majority of these base their implementations on the loopy belief propagation algorithm (Rao, 2006; Steimer et al., 2009; Siegelmann and Holzman, 2010; Litvak and Ullman, 2009). Except for Siegelmann and Holzman (2010), to the best of our knowledge, none of these studies proposes a way how these neural structures could emerge through learning from examples. The model of Siegelmann and Holzman (2010) is formulated on a more abstract level. It is based on the observation that belief propagation (message passing) requires only three arithmetical operations: summation, multiplication, and division (for normalization). Their network model is based on symbolic computational units (interpreted as multicompartment neurons) that carry out these arithmetical operations on real numbers. The resulting real numbers are interpreted as probabilities or messages that are sent to other units during belief propagation. Estimates of conditional probability tables are extracted from examples through online accumulators, assumed to be implemented as plasticity of the weight of a dendritic branch that represents a specific value assignment for a set of random variables (more precisely, for the Markov blanket of a random variable). Hence, this learning model is not based on synaptic plasticity, but rather on a plasticity mechanism that changes the weight of a whole dendritic branch. We are not aware of an attempt to implement this approach with spiking neurons, or with more local plasticity rules.
An alternative framework for probabilistic inference in neural circuits developed by Ma et al. (2006) and Beck et al. (2008, 2011, 2012) is based on representation of probability distributions in probabilistic population codes. To the best of our knowledge, the question of how the neural implementations in those studies can emerge through learning with local plasticity mechanisms has so far not been addressed.
We have focused in this paper on the task of learning time-invariant distributions p* over static patterns. Complementary to this, in several studies (Deneve, 2008; Rezende et al., 2011; Brea et al., 2013; Kappel et al., 2014) the authors developed neural network models for learning time-varying distributions, restricted to dynamical Bayesian networks that do not have dependencies between the RVs in the same time step, which simplifies the learning. In these models, the network learns to reproduce sequences of patterns, by developing latent representations as a memory about the recent history of patterns, and learning the stochastic transitions between the patterns in the sequence. In contrast to this, the neural networks in our approach learn a probability distribution of static patterns as their stationary distribution, where the distribution can contain arbitrary dependencies between the random variables without any restrictions.
The problem of learning a probability distribution from examples has been well studied in the artificial neural network community. The Boltzmann machine is one of the earliest developed neural networks that can learn general probability distributions (Ackley et al., 1985). The learning in the Boltzmann machine is however difficult for learning higher-dimensional probability distributions with a larger number of RVs (Hinton, 2002; Carreira-Perpinan and Hinton, 2005). Building on the Boltzmann machine idea, more recently developed deep belief networks have considerably improved the efficiency and scalability of learning by using a Boltzmann machine with a two-layer bipartite graphical model structure, called restricted Boltzmann machine, which is easier to train than the general Boltzmann machine (Hinton et al., 2006). Deep belief networks learn multilayer latent representations of the input data in a generative model by training layer-by-layer restricted Boltzmann machines. As in our approach, the learned probability distribution is embodied as a stationary distribution of the network states. However, the structure of Boltzmann machines and deep belief networks exhibits symmetric weights between the neurons which are not found in biological networks of neurons, and also the biological plausibility of layerwise training and the learning rules in these networks is not clear.
These approaches derive their learning rules from the maximum likelihood learning principle. Our learning approach for network of interconnected learning modules, on the other hand, is more reminiscent to maximizing the pseudo-likelihood (Besag, 1975), an alternative parameter estimation method in statistical learning, where the objective function can be formulated through the Kullback–Leibler divergences between the target and the model conditional distributions of one variable given the rest of the RVs. The difference is that in the pseudo-likelihood objective function the conditional distributions are all derived from a single probabilistic model, whereas in our approach each learning module learns a separate generative model of a marginal of the target probability distribution.
Experimentally testable predictions of our model and other questions for further research
Our model makes significantly different predictions compared with previous models for memory in neural networks with regard to the architecture of the neural networks involved. Models based on Hopfield networks and Boltzmann machines predict that memories are stored in homogeneous networks of only excitatory neurons with symmetric synaptic connections. In contrast, our model predicts that memories are stored in large assemblies of highly structured generic microcircuit motifs, each consisting of excitatory and inhibitory neurons. Our model gives rise to a concrete hypothesis, why different species have different learning capabilities, which cannot be explained in terms of the different numbers of neurons in their brains. It proposes that the structure or structural predisposition of interconnections between neurons is an important factor for learning performance. In particular, it predicts that the superior learning capabilities result from a genetically more precisely structured interaction of excitatory and inhibitory neurons. Our model of a probabilistic learning module (Fig. 2) proposes in fact two different functional roles of inhibitory neurons: lateral inhibition among excitatory neurons that induces each of them to specialize on different presynaptic firing patterns, and another type of inhibition that prevents hidden neurons that learn a probabilistic relationship between random variables  for a specific value z = l, to engage plasticity for examples
for a specific value z = l, to engage plasticity for examples  with z ≠ l. This architecture provides concrete hypotheses for the analysis of data on the role of inhibitory neurons in the organization of plasticity (Caroni, 2015; Letzkus et al., 2015).
with z ≠ l. This architecture provides concrete hypotheses for the analysis of data on the role of inhibitory neurons in the organization of plasticity (Caroni, 2015; Letzkus et al., 2015).
Furthermore, our model for an atomic probabilistic learning module predicts that pyramidal cells within a network can represent probabilistic, rather than only deterministic relationships. This can in principle be tested experimentally by exciting (eg, through optogenetic methods) a subset A of these neurons, and observe the resulting firing probability of pyramidal cells B. Furthermore our model predicts that this firing probability of neurons in B can be changed upward through trials where both neurons in A and B are made to fire, and changed downward through trials where neurons in A are made to fire and neurons in B are inhibited.
In contrast to preceding memory models, our model does not predict that synaptic connections between neurons are in general symmetric. This would actually be impossible for synaptic connections between excitatory and inhibitory neurons. But also for synaptic connections between pyramidal cells in the cortex a symmetry of synaptic weights between them is not really consistent with the currently available experimental data (Song et al., 2005; Haeusler et al., 2009, their Fig. 4). With regard to the plasticity mechanisms involved, our model points to an essential contribution of intrinsic plasticity of the excitability of pyramidal cells for memory formation (Mozzachiodi and Byrne, 2010).
An interesting functional prediction of our model is that memory recall cannot only take the form of input completion (like in a Hopfield network), but can engage the full power of probabilistic inference. Furthermore, it proposes that this inference is implemented through the inherent stochastic dynamics of networks of neurons in the brain. Such implementation has previously already been proposed on the basis of data from cognitive science (Denison et al., 2013; Vul and Pashler, 2008). Furthermore our model predicts that memory recall and imagination of possible scenarios are closely related brain computations, that engage similar network mechanisms. This prediction appears to be consistent with recent experimental data, which suggest that memory recall and imagination/fabulation engage largely the same brain systems (Schacter, 2002).
Finally, our model predicts that the development of suitable brain networks that store basic insights about typical causal roles and dependencies of the objects and phenomena we encounter is essential for learning. This prediction is in line with experimental results from cognitive science, which argue that such basic knowledge about dependencies in the real world is already known to 2-year-old children (Landau et al., 1988). Because our learning approach emphasizes the role of probabilistic inference, it also provides a theoretical framework for integrating innate or previously learnt knowledge in the form of priors.
The learning paradigm that we have presented was designed to provide an alternative to other neural network models for higher-level memory. Such higher-level memory system in the brain receives high-dimensional inputs y from numerous brain areas, in particular also higher-level features that are extracted from sensory inputs by other learning systems.
It is at this point an open question to what extent the proposed model for learning in networks of spiking neurons can also provide insight into the organization of lower level learning systems in the brain, for example in the visual system. The underlying mathematical approach is quite general, and guarantees convergence to an internal model for any external distribution p* over discrete RVs that generates the examples y that are presented to the network. How good this internal model will become is related to the question how well p* can be approximated by a Bayesian network with small degrees of nodes, or more generally, by a simplified distribution where all RVs have small Markov blankets. However, a precise answer to this question is even more difficult, because our model is in principle also able to approximate some distributions with large Markov blankets, see the remarks at the end of Results section “Small numbers of hidden neurons in the learning modules often suffice.” Numerical tests for a number of practically relevant distributions p* are likely to provide further insight into this question.
In principle, it is also possible to boost the learning capability of our approach by stacking multiple copies of the learning network. The α neurons in the network learn to encode salient combinations of values of different RVs, similarly as feature detectors on the first hidden layer of a deep learning network. Hence, it would make sense to send the output of these α neurons also as input to a version of the same type of learning network on a second level. One would then expect that the second level network learns in the same unsupervised manner to detect and represent salient combinations of values in these α neurons. The analysis of the performance of such a stacked learning architecture based on spiking neurons and STDP is a topic for future research.
Summary
Altogether, we have shown that some forms of probabilistic inference can be learnt through STDP, even in cases where the nontrivial “explaining away” effect occurs (Figs. 6–9). We propose, that this new paradigm for network learning provides an alternative to previous models for associative learning that were based on learning categorical rather than probabilistic associations. In addition, in contrast to earlier memory models, this new model is compatible with basic properties of biological networks of neurons, such as spikes, trial-to-trial variability, stereotypical microcircuit motifs, and STDP.
Footnotes
↵1 The authors declare no competing financial interests.
↵2 D.P. and W.M. designed research; D.P. analyzed data; D.P. and W.M. performed research; D.P. and W.M. wrote the paper.
↵3 This work was partially supported by the European Union project FP7-604102 (Human Brain Project). We thank Stefan Habenschuss for helpful comments on an earlier version of the paper.
This is an open-access article distributed under the terms of the Creative Commons Attribution 4.0 International, which permits unrestricted use, distribution and reproduction in any medium provided that the original work is properly attributed.
References
In this issue

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
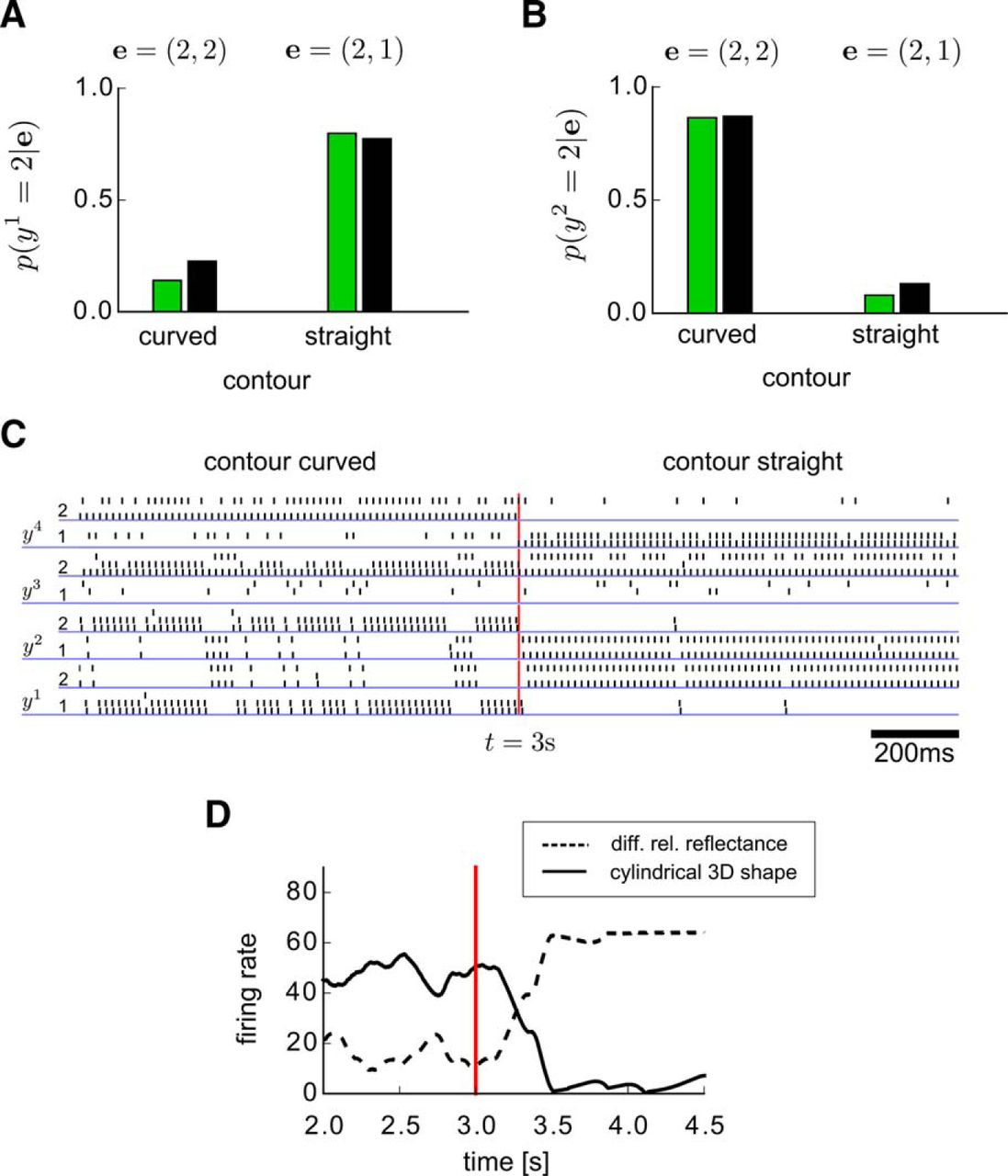{kind=link}



